永洪社区
标题: 数据集中新建分析算法 [打印本页]
作者: Lydia 时间: 2024-12-6 16:18
标题: 数据集中新建分析算法
产品支持在数据集上创建分析算法,数据集上创建分析算法后,使用该数据集的报告都可以使用。要使用分析算法,需要先配置Rserver,配置方法参考《R安装、启动》和《R配置》。
1.功能说明
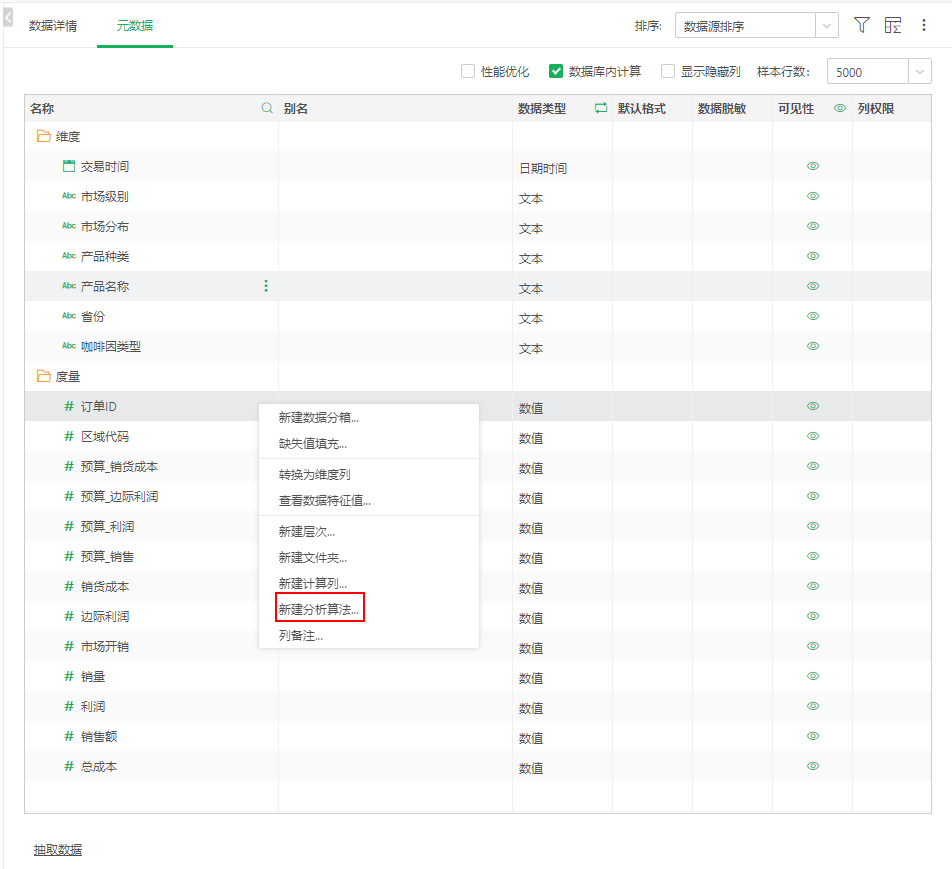
进入【创建数据集】页面,打开数据集“咖啡中国市场销售数据”,进入元数据页面,点击数据列“更多”按钮,选择【新建分析算法】,如下图。
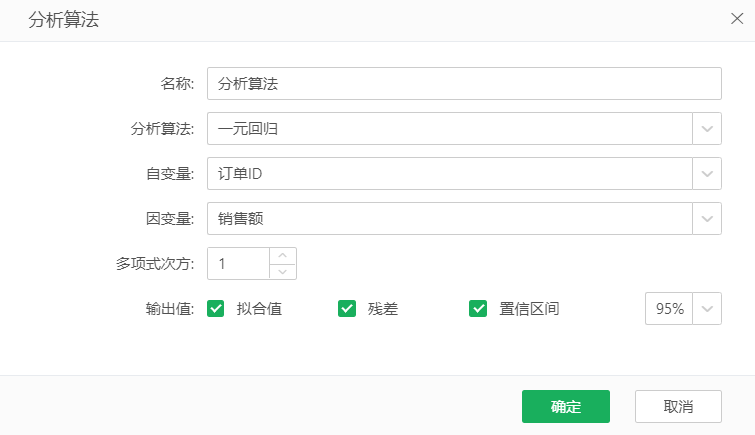
在弹出的“ 分析算法” 窗口中输入名称,选择分析算法类型,选择并设置算法需要的数据列或属性值,或自定义R脚本,返回新的R字段(输出值)。根据分析算法生成R字段,作用域是当前数据集,所有使用该数据集的报表都能使用此数据集上的R 字段。
数据集中可以用四种分析算法进行快速绘图。支持一元回归、K-means 聚类、HoltWinters 时序分析以及定制。
2.算法说明
2.1 一元回归
回归分析是一种应用非常广泛的分析模型,主要用来表示因变量(Y)与自变量(X)之间的函数关系。当因变量和自变量为线性关系时,即一元一次线性关系,因变量(Y)与自变量(X)的图形表示为直线。一元一次线性回归的函数为y = ax+b,其中y是因变量,x是自变量,a和b为常数。如果自变量的指数(幂)大于1,则因变量(Y)与自变量(X)之间是非线性关系,图形表示为曲线。
【自变量】x,从下拉列表中选出需要作为自变量的字段。
【因变量】y,从下拉列表中选出需要作为因变量的字段。
【多项式次方】表示自变量与因变量的N次方函数关系,默认为1,如果是2则表示一元二次函数关系。
【输出值】【拟合值】:被勾选时,会得到一个拟合值字段。根据训练数据得到回归模型后,会对给定的样本值(x1,x2,...,xn)做预测,预测结果即为拟合值,是(y1,y2,...,yn)的估计值。
【输出值】【残差】:被勾选上时,会得到一个残差字段。其结果是y的实际值减去拟合值。
【输出值】【置信区间】:被勾选上时,根据Level计算出置信区间的范围,默认Level是95%。
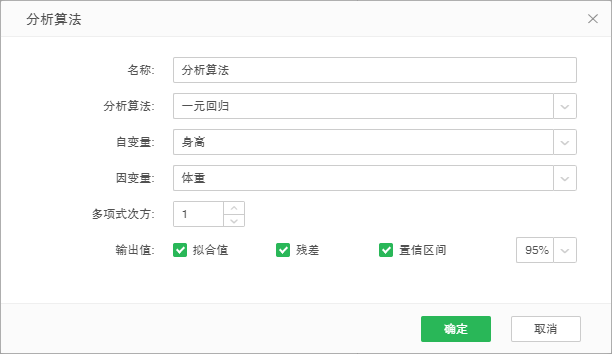
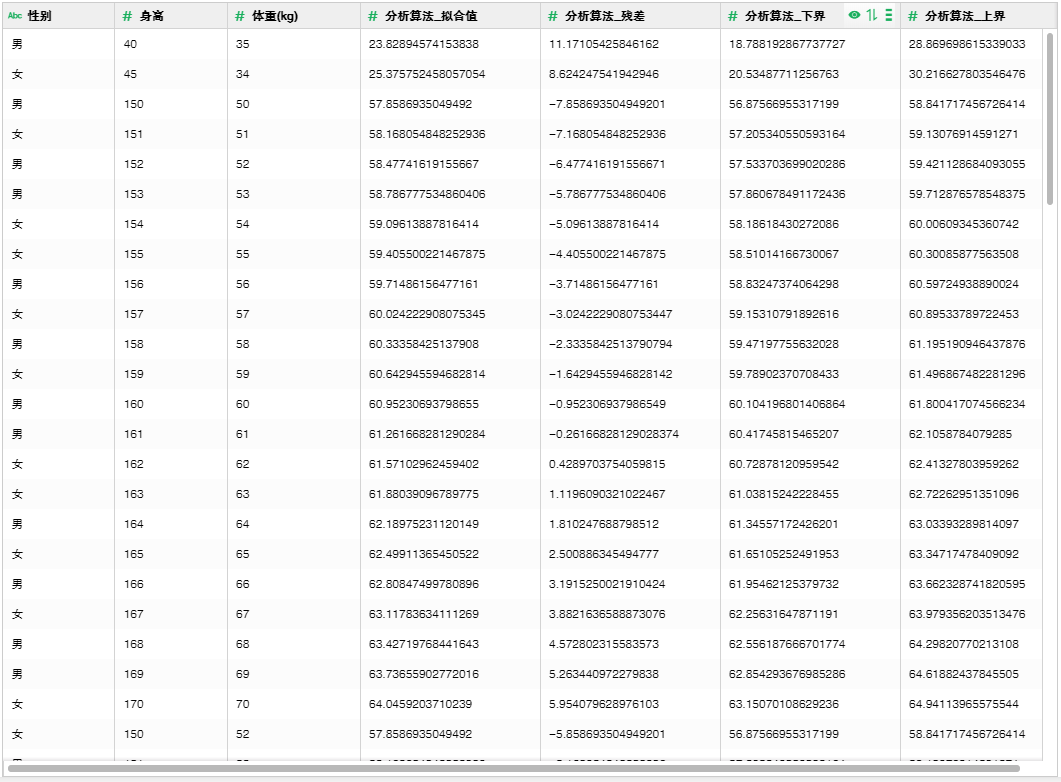
如下图,对一系列身高和体重的值进行回归分析。收集一系列身高和体重的值,身高为自变量,体重为因变量,使用一元回归分析算法找出所创建模型的数学方程。根据数学方程,计算体重的拟合值。在数据集上创建分析算法:
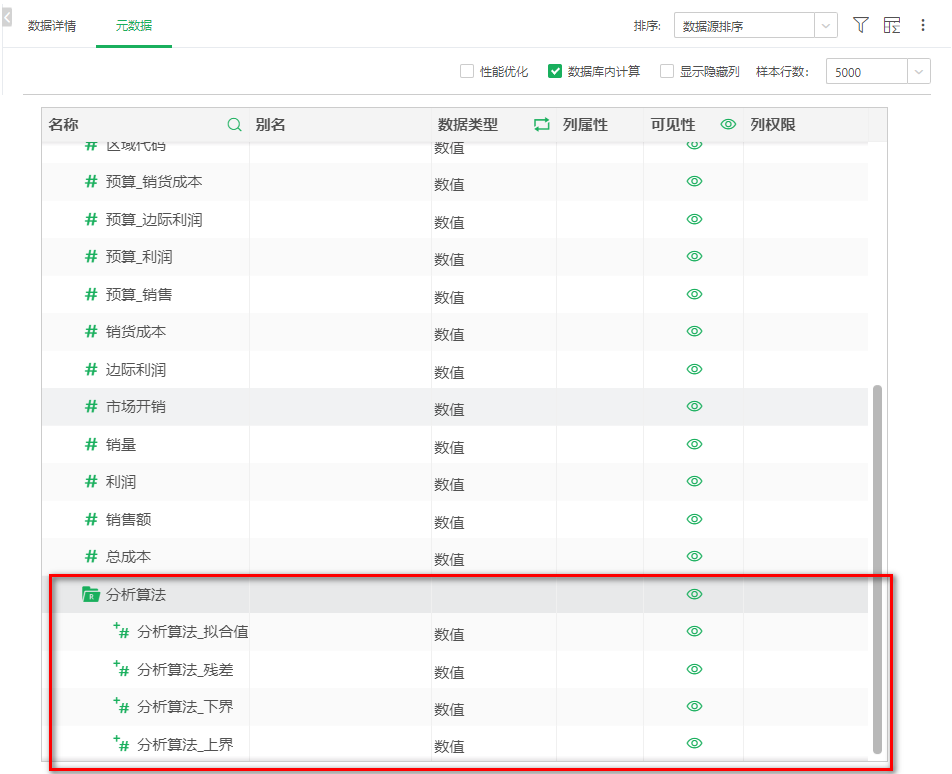
输出结果如下图,
2.2 K-Means聚类
K-Means聚类要指定聚类的分类个数N,随机取N个样本作为初始类的中心,计算各样本与类中心的距离并进行归类,所有样本划分完成后重新计算类中心,重复这个过程直到类中心不再变化。在R中使用kmeans函数进行K-means聚类。
kmeans(data,centers=3,nstart=10),其中centers 参数用来设置分类个数,nstart 参数用来设置取随机初始中心的次数,即运行kmeans 方法的次数,我们在用kmeans 函数时,默认取10。
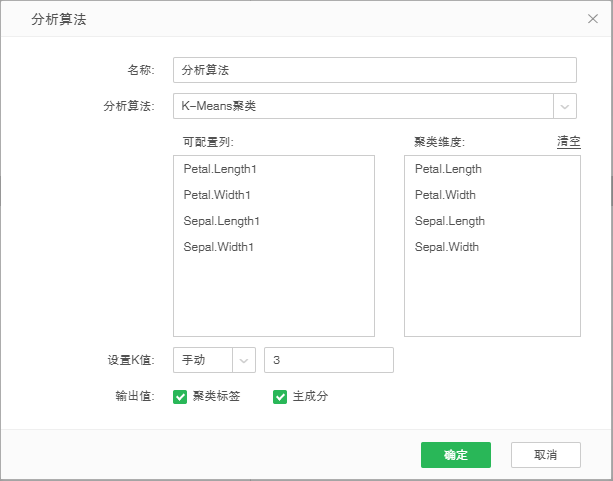
【聚类维度】聚类的样本集。从左侧的可配置列中选择需要作为聚类维度的字段直接拖入到聚类维度框中。
【设置K 值】分类的个数。可以手动输入分类个数,也可以输入最大K值,系统根据轮廓系数计算出最佳的K值。
【输出值】【聚类标签】每个样本所属的类别。
【输出值】【主成分】对聚类的维度做主成分分析,取最重要的两个成分。
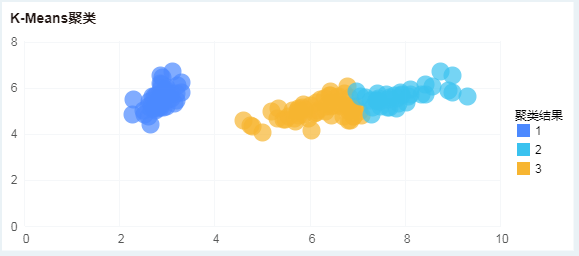
假设去掉类别列,根据四种属性对三种花进行分类。在图表上创建K-means 聚类分析,如图,
聚类结果如图,
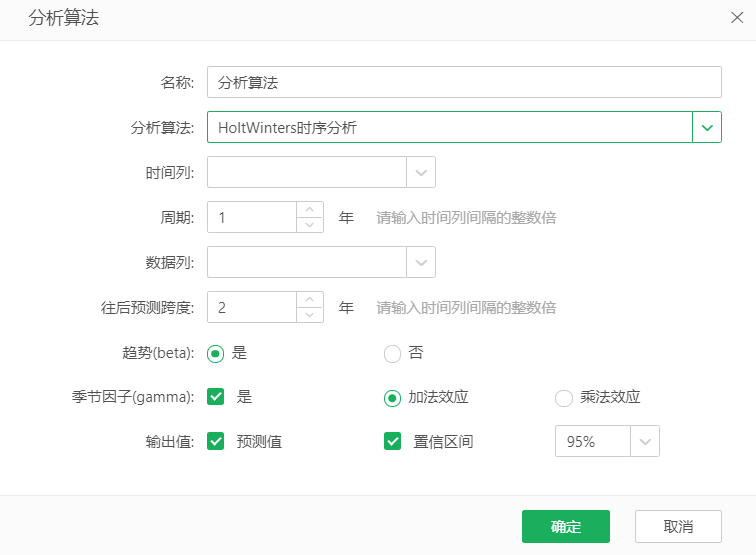
2.3 HoltWinters 时序分析
HoltWinters 时序分析通过考虑水平趋势和季节性趋势,对一段时间内、等时间间隔的采样数据进行分析,以预测未来一段时间的数据。即根据已知的历史数据,预测未来的数据。
【时间列】选择时间字段。根据选择的时间字段的数据,自动算出时间间隔。
【数据列】选择数据字段。在报表组件绑定的数据集上新建分析算法,或使用图表的快速分析算法时,需要选择聚合函数,这样将按时间列进行分组,数据列进行聚合,在此分组聚合之后的数据上进行时序分析。
【周期】需填入时间间隔的整数倍,根据周期和时间间隔(周期/ 时间间隔)算出频率,即单位时间内的观测数。根据时间间隔,系统会自动往周期填入一个合理的数值,此数值也可手动修改。
【往后预测跨度】往后预测的时间跨度,需填入时间间隔的整数倍。选择时间列后,系统会自动填入一个合理的数值,此数值也可进行手动修改。
【趋势(beta)】是否考虑纵向趋势。默认是被勾选,表示按纵向趋势拟合。
【季节因子(gamma)】是否考虑季节性趋势。如果设置为不勾选(FALSE),则非季节性模型拟合。如果设置为勾选,则进行季节性模型拟合。季节性模式可以是加法效应(additive)和乘法效应(multiplicative)。加法效应默认勾选,表示按季节性加法的趋势增长。当乘法效应被勾选时,表示按季节性乘法趋势增长。季节性模型拟合时,需满足一个周期内至少有两个数据点,即频率大于等于2,且时间序列至少包含2 个周期。
【输出值】【预测值】被勾选时,会得到一个拟合值字段。其结果是根据得到的模型,对往后预测的时间跨度做预测,算出预测值。
【输出值】【置信区间】被勾选上时,根据Level 算出估计值的上界和下界,默认Level 是95%。
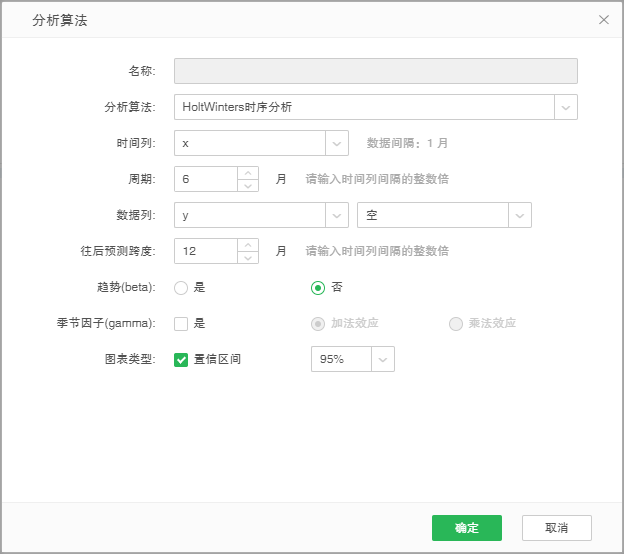
假设数据是从1957 年1 月到1958 年12 月的数据,时间间隔为1 月,用HoltWinters 时序分析,选择周期6 个月,往后预测跨度12 个月。
如果趋势(beta)选择否,季节因子(gamma)不勾选。如下图,
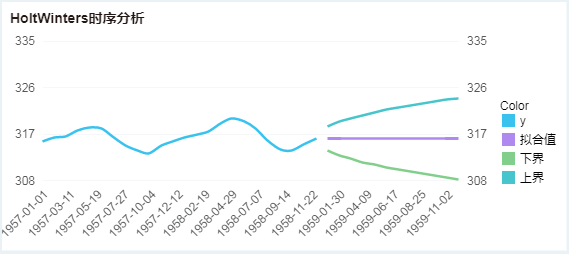
预测结果如图,
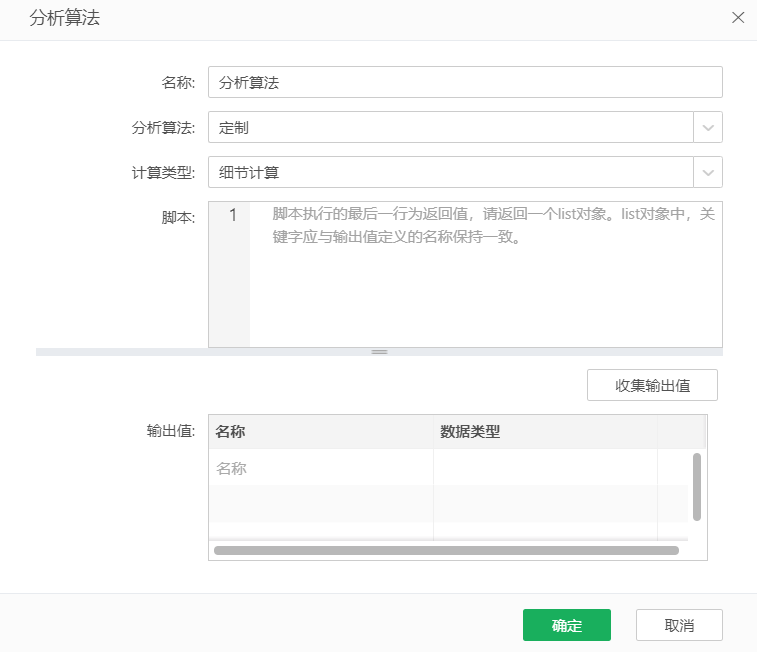
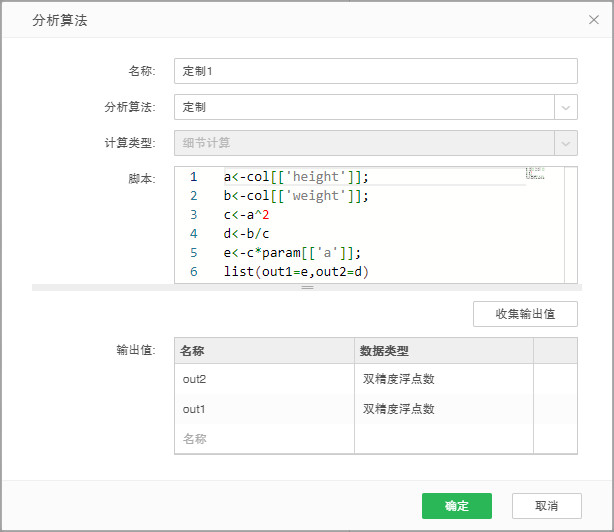
2.4 定制
通过定制,用户可自定义分析算法。
【计算类型】在连接数据的元数据区,默认细节计算处于置灰状态。在组件绑定数据集,默认细节计算处于选中状态。其下拉框中有细节计算和聚合计算,细节计算和聚合计算的区别是:聚合计算出来的R字段为聚合字段。
【脚本】输入脚本内容。可以通过col[[“xxx”]] 来传入数据集中对应列的值,xxx 为列的名称;也可以通过param[[“xxx”]]来传入参数值,xxx 为参数名称。对于定制脚本,R 将最后执行的代码行的结果作为返回值返回。Yonghong 产品中要求返回值必须是list 对象,包含若干返回值列,如list(out1=a, out2=b),其中out1,out2 为返回值列的名称,而a,b为相应返回值列的取值,可以是常数或向量。
其他R 脚本请参考R 官网。
定制举例如下图,
| 欢迎光临 永洪社区 (http://club.yonghongtech.com/) |
Powered by Discuz! X3.4 |