对于一个企业来说,高层看意义,中层看结论,基层看落地,数据日报、周报、月报可以监控销售个人在实际执行过程中的销售动态,而数据季度报、年报可以反映一个销售策略是否与实际的业务场景切合。 可见数据日报在我们日常工作中必不可少,本文使用案例数据,构造销售收入、销售单量等关键性指标,借助Python工具一键生成数据日报,下面一起学习吧! 示例工具:anconda3.7
本文讲解内容:办公自动化
适用范围:Python自动生成数据日报 导入数据 导入报表数据,包含销售日期,员工编号,销售员等七个字段。 import pandas as pd from datetime import datetime df=pd.read_excel(r'C:\Users\尚天强\Desktop\销售数据明细.xlsx',parse_dates=['销售日期']) df.head()#数据预览
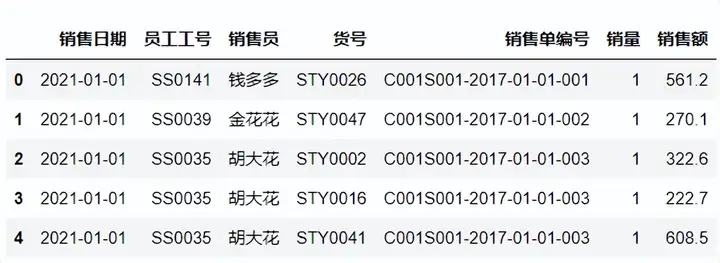 查看数据属性,其中销售日期为日期类型,销量和销售额为数值类型,其他均为文本数据类型。 df.info()#查看数据属性
 计算指标 计算指标设定,设置本文需要计算的指标,指标计算如下: - 收入=销量*销售额
- 单量=销量汇总
- 货品数=货品数去重
- 收入环比:本月收入/上月收入-1
- 单量环比:本月单量/上月单量-1
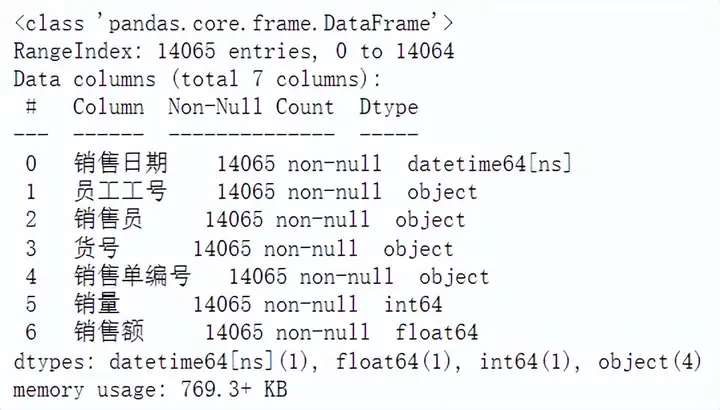
计算本月相关指标 首先选取本月的数据,本月截止到2021年12月25日的数据,分别计算本月截止12月25日收入、本月截止12月25日单量、本月截止12月25日货品数。 the_month=df[(df['销售日期']>=datetime(2021,12,1))&(df['销售日期']<=datetime(2021,12,25))] shouru1=(the_month['销量']*the_month['销售额']).sum()#本月截止12月25日收入 danliang1=the_month['销量'].sum()#本月截止12月25日单量 huopin1=the_month['货号'].nunique()#本月截止12月25日货品数 print("本月截止12月25日收入为{:.2f}元,单量为{}个,货品数为{}个".format(shouru1,danliang1,huopin1))
本月截止12月25日收入为369242.50元,单量为728个,货品数为227个。 计算上月相关指标 同时选取上月同期的数据,数据范围11月1日到11月25日的数据,分别计算上月同期的收入、上月同期的单量、上月同期的货品数。 last_month=df[(df['销售日期']>=datetime(2021,11,1))&(df['销售日期']<=datetime(2021,11,25))] shouru2=(last_month['销量']*last_month['销售额']).sum()#上月截止11月25日收入 danliang2=last_month['销量'].sum()#上月截止11月25日单量 huopin2=last_month['货号'].nunique()#上月截止11月25日货品数 print("上月截止11月25日收入为{:.2f}元,单量为{}个,货品数为{}个".format(shouru2,danliang2,huopin2))
上月截止11月25日收入为586483.80元,单量为777个,货品数为198个。 利用函数进行封装 以上我们可以发现规律,计算本月的相关指标数据与计算上月同期的指标数据计算逻辑是一样的,除了数据选取的日期不一样,我们可以自定义一个函数,用于计算相关的数据指标,简化数据计算的流程。 def get_month_data(df): shouru=(df['销量']*df['销售额']).sum() danliang=df['销量'].sum() huopin=df['货号'].nunique() return(shouru,danliang,huopin)shouru1,danliang1,huopin1=get_month_data(the_month)#计算本月数据指标 shouru2,danliang2,huopin2=get_month_data(last_month)#计算上月数据指标 print("本月截止12月25日收入为{:.2f}元,单量为{}个,货品数为{}个".format(shouru1,danliang1,huopin1)) print("上月截止11月25日收入为{:.2f}元,单量为{}个,货品数为{}个".format(shouru2,danliang2,huopin2))
本月截止12月25日收入为369242.50元,单量为728个,货品数为227个,上月截止11月25日收入为586483.80元,单量为777个,货品数为198个。 计算环比 构建一个DataFrame,填入具体的计算指标数值,计算环比数据。 ribao=pd.DataFrame([[shouru1,shouru2], [danliang1,danliang2], [huopin1,huopin2]], columns=['本月','上月'],index=['收入','单量','货品数'])ribao['环比']=ribao['本月']/ribao['上月']-1 ribao['环比']=ribao['环比'].apply(lambda x:format(x,'.2%')) ribao
 可以将具体的数据日报导出到本地。 ribao.to_excel(r'C:\Users\尚天强\Desktop\数据日报.xlsx',index=False)
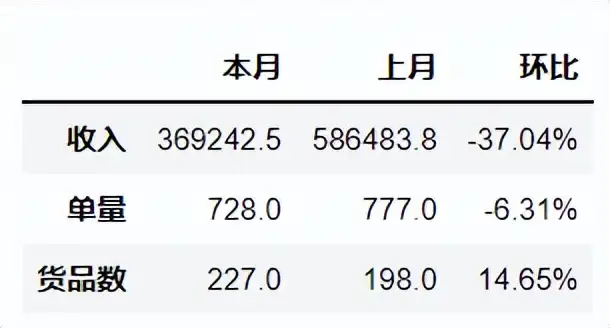
计算每月的销售额、销量数据情况 计算每月的销售额、销售数据情况,使用groupby函数,同时aggregate函数自定义数值的计算方式,数据结果如下。 df['销售月份']=df['销售日期'].astype(str).str[0:7].str.replace('-','') df_group=df.groupby("销售月份").aggregate({"销售额":"sum","销量":"sum"}) df_group
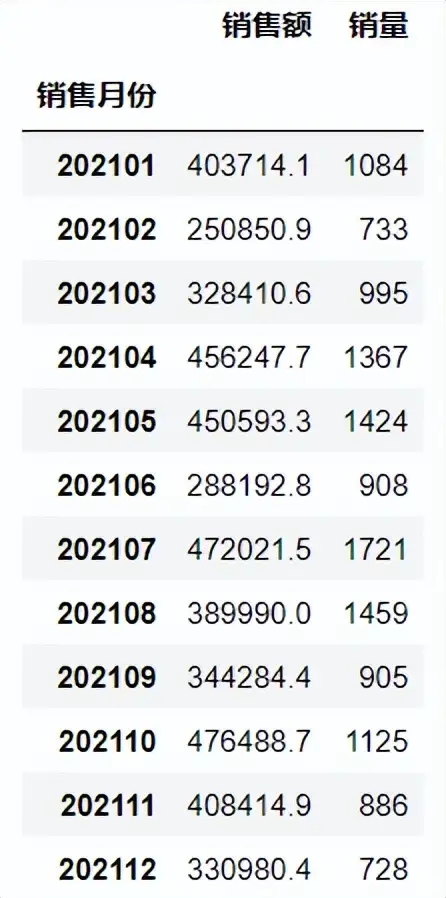 数据可视化 导入pyecharts库,制作组合图,由图像可以看出,截止21年12月25日数据,21年7月销量最高、12月销量最低、21年10月收入最高、2月收入最低。 from pyecharts import options as opts from pyecharts.charts import Bar, Line from pyecharts.faker import Faker #导入数据 v1 = df_group['销售额'].round(2).tolist() v2 = df_group['销量'].tolist() #柱形图 bar = (Bar() .add_xaxis(df_group.index.tolist()) .add_yaxis("销售额", v1 ,category_gap="60%",gap="10%") #设置柱形间隙宽度 .extend_axis(yaxis=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter="{value} 单"), min_=0,max_=1750))#设置次坐标轴坐标大小 .set_series_opts(label_opts=opts.LabelOpts(is_show=True))#显示数据标签 .set_global_opts(title_opts=opts.TitleOpts(title="21年每月销售额与销量情况"), datazoom_opts=opts.DataZoomOpts(),#添加滚动条 yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter="{value} 元"),min_=0,max_=850000)))#设置主坐标轴坐标大小 #折线图 line = Line().add_xaxis(df.index.tolist()).add_yaxis("销售量", v2, yaxis_index=1, is_smooth=True) #组合图 bar.overlap(line) #在线显示 bar.render_notebook() ###bar.render(r'C:\Users\尚天强\Desktop\销售日报.html')
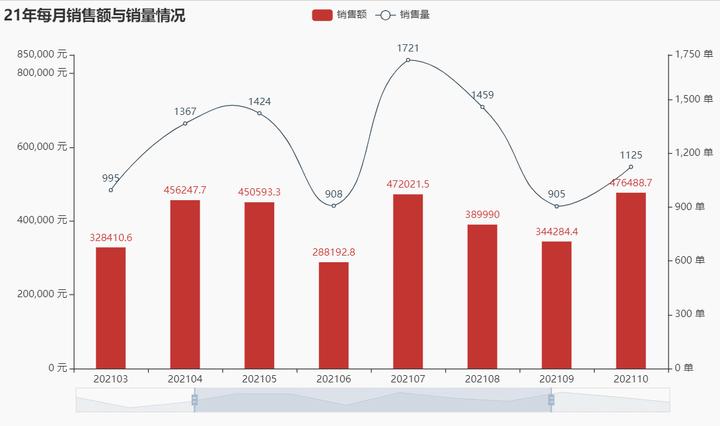
以上我们就完成了一个常规的数据日报,根据具体的数据变化情况可以跟进下一步的销售动态,这里的数据日报比较简单,在实际数据报表制作中,比这个指标复杂的多,表现在指标繁复,计算逻辑复杂,需要数据分析师不断地优化计算流程。
文章源自:大话数据分析
|












