永洪社区
标题: Python办公自动化,如何数据选取,减少数据冗余 [打印本页]
作者: 喝酸奶不舔盖 时间: 2024-6-26 17:00
标题: Python办公自动化,如何数据选取,减少数据冗余
本帖最后由 喝酸奶不舔盖 于 2024-6-26 17:06 编辑
一张表中通常会包含很多字段,造成数据冗余,在做数据分析时,我们仅需要提取数据分析所需要的字段,这里就需要用到数据选取的知识点。
本文构建数据表做数据索引,然后对数据内容进行调整,包含修改数据类型、去除空格、数据替换、截取字符等,最后做数据规整。
一、构建数据表
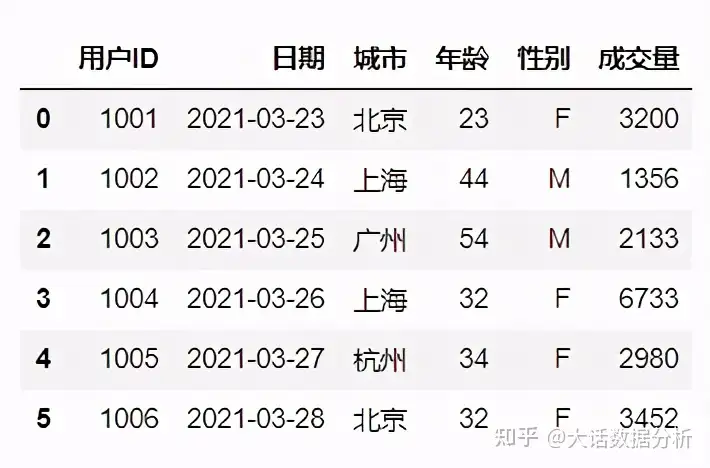
首先导入常用的库,设置一些数据字段,构建一张数据表。
import pandas as pd import numpy as np import datetime df = pd.DataFrame({'用户ID':[1001,1002,1003,1004,1005,1006], '日期':pd.date_range(datetime.datetime(2021,3,23),periods=6), '城市':['北京', '上海', '广州', '上海', '杭州', '北京'], '年龄':[23,44,54,32,34,32], '性别':['F','M','M','F','F','F'], '成交量':[3200,1356,2133,6733,2980,3452]}, columns =['用户ID','日期','城市','年龄','性别','成交量']) df
二、数据索引
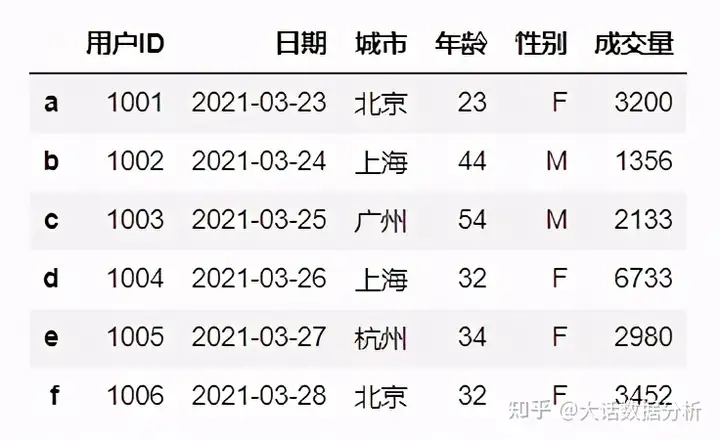
1、索引修改
#修改索引,直接赋值给Index即可 df.index=list('abcdef') df
2、数据索引
索引某行,有三种方法,一种是loc按照名字索引,另一种是iloc按照下标索引,Ix是loc和iloc的混合,既能按索引标签提取,也能按位置进行数据提取。
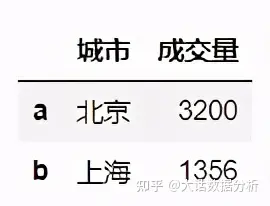
#索引两列 df.loc[:,['城市','成交量']]
 #索引前两行,两列 df.loc[['a','b'],['城市','成交量']]
#索引前两行,两列 df.loc[['a','b'],['城市','成交量']]
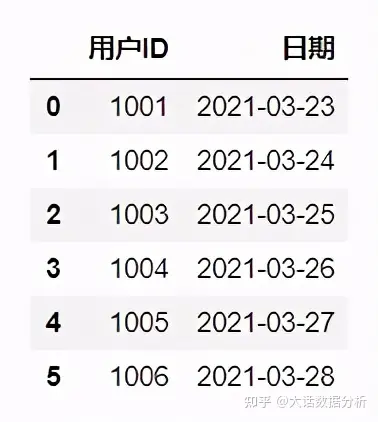
 #获取第一列、第二列数据 df.iloc[:,0:2]
#获取第一列、第二列数据 df.iloc[:,0:2]
 #获取第二行、第三行,第一、二、三列的数据 df.iloc[[1, 2],[0, 1, 2]]
#获取第二行、第三行,第一、二、三列的数据 df.iloc[[1, 2],[0, 1, 2]]
 # 仅取出第1行的数据 df.iloc[0]
# 仅取出第1行的数据 df.iloc[0]
 #索引全部行数据 df.iloc[:,[0, 1, 2]]
#索引全部行数据 df.iloc[:,[0, 1, 2]]
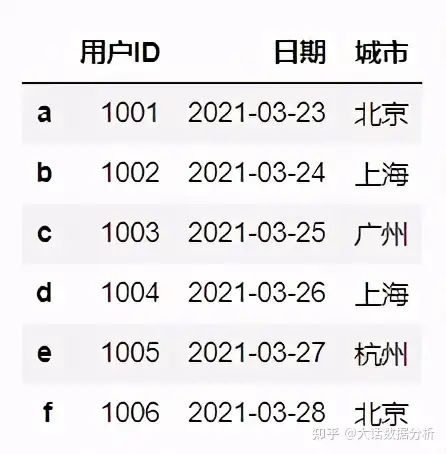 #使用ix按索引标签和位置混合提取数据 df.ix[:'2021-03-26',:3]
#使用ix按索引标签和位置混合提取数据 df.ix[:'2021-03-26',:3]

3、条件筛选
#筛选性别为F的数据 df[df['性别']=='F']
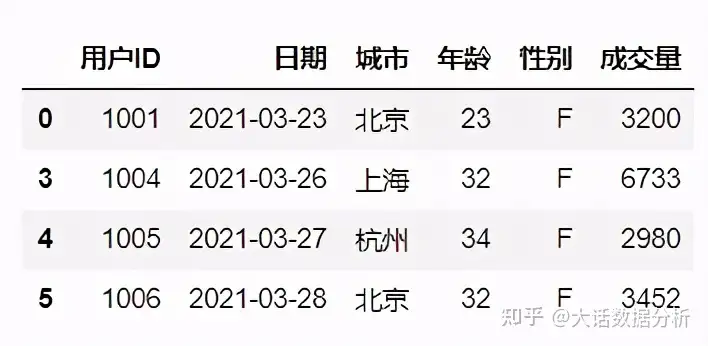 df[(df['城市']=='北京') & (df['年龄']>30)]
df[(df['城市']=='北京') & (df['年龄']>30)]
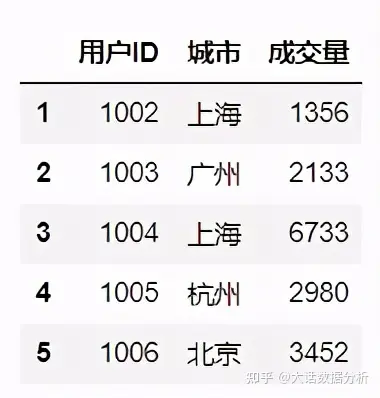
 #布尔索引加普通索引选择指定的行和列 df[df['年龄']>30][['用户ID','城市','成交量']]
#布尔索引加普通索引选择指定的行和列 df[df['年龄']>30][['用户ID','城市','成交量']]
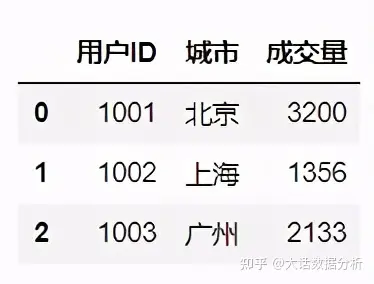
 #切片索引加普通索引选择指定的行和列 df.iloc[0:3][['用户ID','城市','成交量']]
#切片索引加普通索引选择指定的行和列 df.iloc[0:3][['用户ID','城市','成交量']]
三、数据内容调整
1、修改数据类型
#数据类型修改 df.dtypes
 #将用户ID数值类型转化为字符串类型df['用户ID'] = df['用户ID'].astype(str) df['用户ID'].dtype
#将用户ID数值类型转化为字符串类型df['用户ID'] = df['用户ID'].astype(str) df['用户ID'].dtype

2、去除空格
#去除字段中的空格 df = pd.DataFrame({'城市':['北京 ', ' 上海', ' 广州 ', '上海', ' 杭州 ', ' 北京']}) df['城市']
 df['城市'].str.strip()
df['城市'].str.strip()

3、数据替换
df['城市'] = df['城市'].replace('北京','北京市') df['城市']

4、截取部分字符
#截取部分字符到日期日 df['日期'] = df['日期'].astype(str) df['日期'].str[8:10]

四、数据规整
1、数据排序
#排序,以成交量降序排列 df.sort_values(['成交量'],ascending=False)
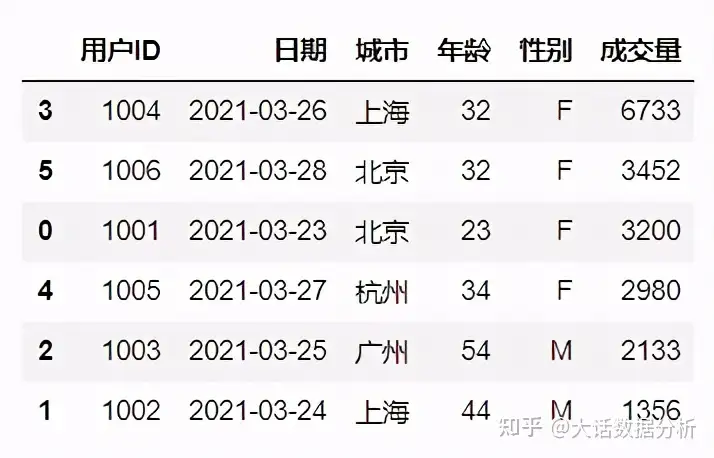
2、数据分类
#使用where进行判断,条件满足为第一个值,不满足则返回第二个值 df['达成情况']=np.where(df['成交量']>3000,'达成量高','达成量低') df
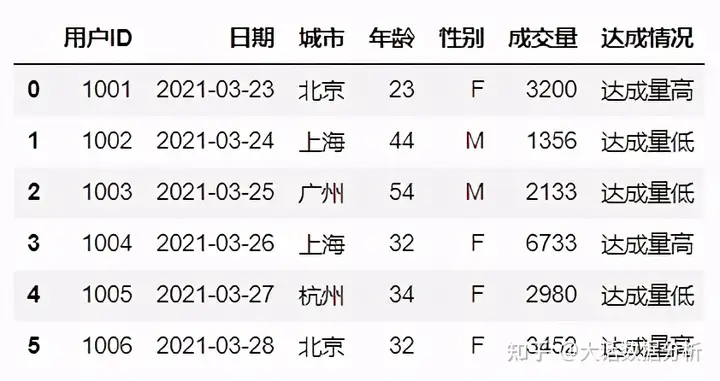
文章源自:大话数据分析
作者: happypanda 时间: 2024-7-28 08:35

| 欢迎光临 永洪社区 (https://club.yonghongtech.com/) |
Powered by Discuz! X3.4 |