本帖最后由 喝酸奶不舔盖 于 2024-6-26 17:36 编辑

下面一起学习,如何使用Python导入.xlsx文件和.csv文件,导入.xlsx文件的参数如下所示,本文讲解我们日常办公所需要的一些参数。
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=False,dtype=None,engine=None, converters=None,true_values=None,false_values=None,skiprows=None, nrows=None,na_values=None,parse_dates=False,date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=True, **kwds)
导入.xlsx文件 使用read_excel命令导入数据,写入路径即可。 #导入数据 df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx") df.head()
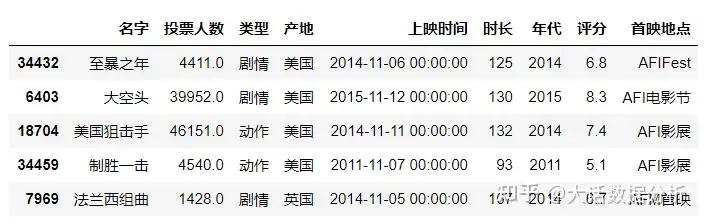
nrows
导入前4行数据。
#导入前4行数据 df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",nrows=4) df
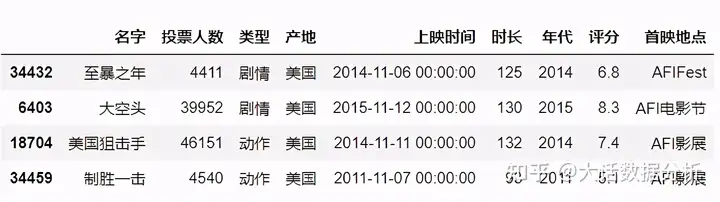
sheet_name
指定导入的sheet表,在首映地点中选择中国首映的sheet表。 #导入具体的sheet数据 df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",sheet_name = "中国首映") df.head()
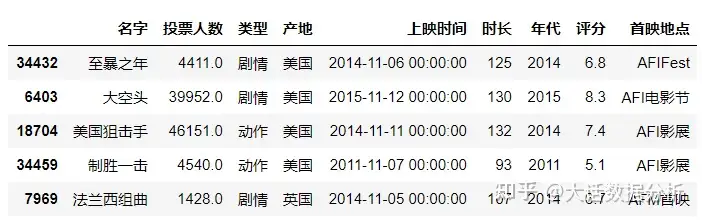
header
指定第一行是否为列名,header=0,表示数据第一行为列名,header=None,表明数据没有列名。
#header为0时,第一行作为列索引 df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",header = 0) df.head()
index_col
指定列作为行索引。
#index_col为1时,第二列作为行索引 df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",index_col = 1) df.head()
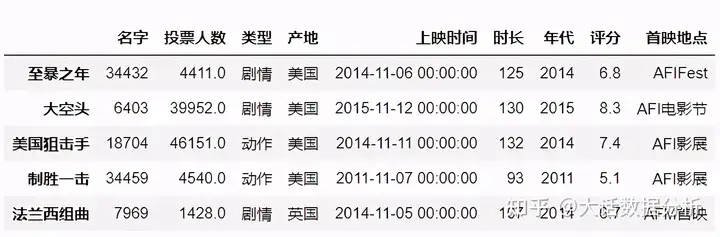
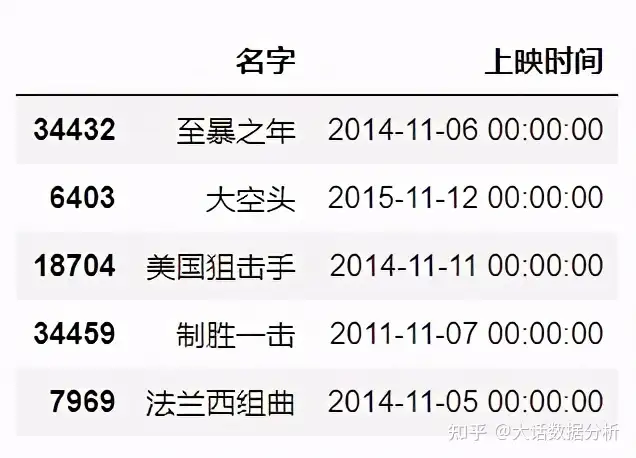
usecols
可以指定读取的列名。
#选择第二列,第六列数据 df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",usecols =[1,5]) df.head()#这里使用一个小技巧,将带空格的字符串变为列表形式。'名字 上映时间'.split()#选择特定的列 df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",usecols =['名字', '上映时间']) df.head()

这里发现指定具体的列名称时无法选择列,我们使用切片索引选择特定的列。
#选择特定的列 df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx") df=df.loc[:,['名字', '上映时间']] df.head()
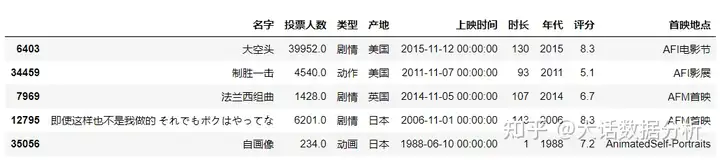
skiprows
跳过多少行再读取数据。 #跳过第二行和第四行数据 df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",header=0,skiprows=[1,3]) df.head()
names
对选取的列重命名。 #对列命名 df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",usecols =[1,5],names=["电影名称","上映日期"]) df.head()

数据类型转化
types 查看字段的数据类型。 df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx") df.dtypes

dtype
转化数据类型。 #转化数据类型 df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",dtype={'投票人数':'int','评分':'int'}) df.dtypes

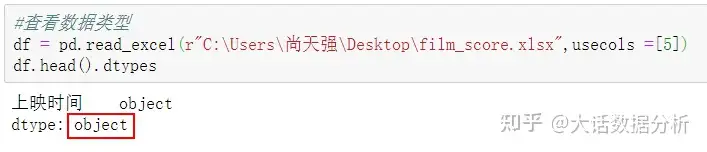
object数据类型转化。
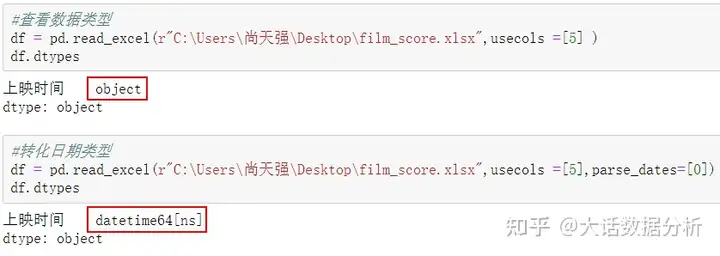
#查看数据类型 df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",usecols =[5]) df.dtypes
 指定解析成日期格式的列。 #转化日期类型 df = pd.read_excel(r"C:\Users\尚天强\Desktop\film_score.xlsx",usecols =[5],parse_dates=[0]) df.dtypes
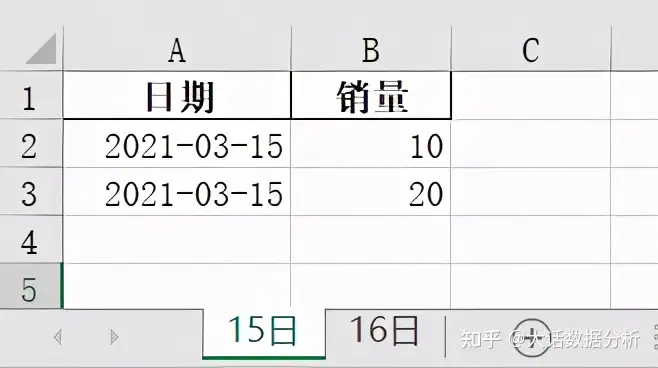
 创建一个时间表。 import pandas as pd from datetime import datetime a={'日期':[datetime(2021,3,15),datetime(2021,3,15)],'销量':[10,20]} b={'日期':[datetime(2021,3,16),datetime(2021,3,16)],'销量':[30,40]} df1=pd.DataFrame(a) df2=pd.DataFrame(b)
使用datetime_format进行日期格式转化。 with pd.ExcelWriter(r'C:\Users\尚天强\Desktop\learn.xlsx',datetime_format='YYYY-MM-DD') as writer : df1.to_excel(writer,sheet_name='15日',index=False) df2.to_excel(writer,sheet_name='16日',index=False)
数据导出
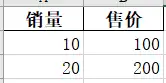
使用to_excel,写入导出的路径,进行数据导出,index=False消行索引。 import pandas as pd a={'销量':[10,20],'售价':[100,200]} df=pd.DataFrame(a) df.to_excel(r'C:\Users\尚天强\Desktop\learn.xlsx',index=False) #取消行索引
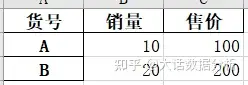
加入行索引,并使用index.name对其命名。
import pandas as pd a={'销量':[10,20],'售价':[100,200]} df=pd.DataFrame(a,index=['A','B']) #加入一个行索引 df.index.name='货号' df.to_excel(r'C:\Users\尚天强\Desktop\learn.xlsx')
float_format
设置浮点型数据的小数位。 na_rep 空值进行填充。
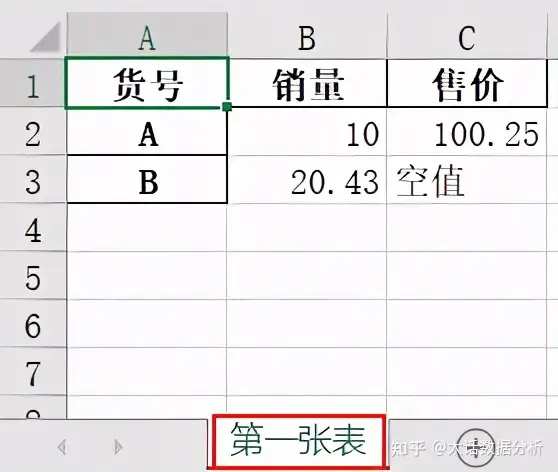
import pandas as pd a={'销量':[10,20.43],'售价':[100.25,None]} df=pd.DataFrame(a,index=['A','B']) #加入一个行索引 df.index.name='货号' df.to_excel(r'C:\Users\尚天强\Desktop\learn.xlsx',sheet_name='第一张表',float_format='%.2f',na_rep='空值')
导入.csv文件
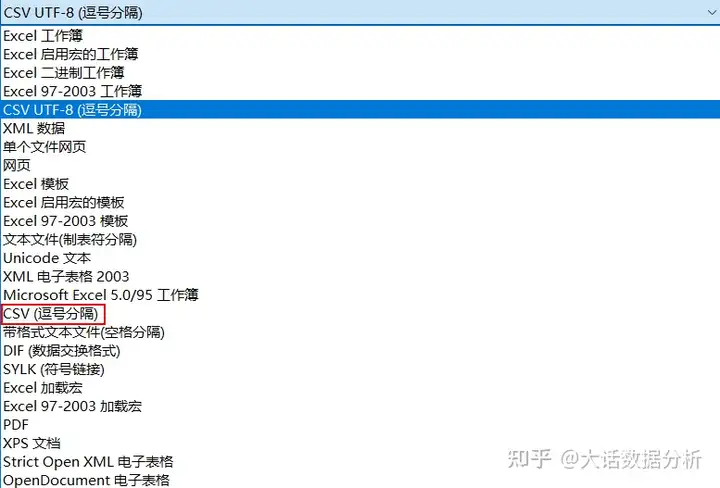
我们常使用的CSV文件有CSV UTF-8(逗号分隔)和CSV(逗号分隔)这两种。
编码方式设置
如果导出的文件为gbk编码方式,导入数据的时候用gbk的编码方式。 encoding 指定数据读入的编码方式。 # 如果导出的文件为gbk编码方式,导入数据的时候用gbk df = pd.read_csv(r"C:\Users\尚天强\Desktop\score.csv",encoding="gbk",nrows =2)#导入前两行 df
中文路径导入数据 当文件路径或文件名为中文时,如果是CSV UTF-8(逗号分隔)的格式文件,需要把编码格式更改为utf-8-sig,如果是CSV(逗号分隔)的格式文件,需要把编码格式更改为gbk。
''' 当文件路径或文件名为中文时,如果是CSV UTF-8(逗号分隔)的格式文件,需要把编码格式更改为utf-8-sig 如果是CSV(逗号分隔)的格式文件,需要把编码格式更改为gbk ''' df = pd.read_csv(r'C:\Users\尚天强\Desktop\cars_scoreCSV.csv',engine="python",encoding="gbk") df.head()
''' 当文件路径或文件名为中文时,如果是CSV UTF-8(逗号分隔)的格式文件,需要把编码格式更改为utf-8-sig, 如果是CSV(逗号分隔)的格式文件,需要把编码格式更改为gbk ''' df = pd.read_csv(r'C:\Users\尚天强\Desktop\cars_scoreUTF-8.csv',engine="python",encoding="utf-8-sig") df.head()
|














