|
拿到一组用户的交易数据,我们如何做数据分析?常规地做法是做用户画像,比如分别对性别、年龄、受教育水平、婚姻状况等做描述统计分析,研究不同的用户特征对于交易金额的影响。
本文使用Python对一组交易金额数据做数据分析,通过对数据进行预处理,包括数据类型转换、重复值判断、缺失值处理、数据分组,对用户做初步画像,下面一起来学习。
示例工具:anconda3.7
本文讲解内容:交易数据用户画像
适用范围:Python用户画像 研究目的 - 性别与交易金额的关系
- 年龄与交易金额的关系
- 不同交易金额区间段人数
数据导入 使用read_excel命令导入数据。 import pandas as pd data=pd.read_excel(r'C:\Users\尚天强\Desktop\个人信息和交易数据.xlsx') data.head()
 打印一下数据形状,本次使用的案例数据共计3000行,6列。 data.shape
(3000, 6) 使用dtypes命令查看数据类型,其中,用户ID为数值类型,交易金额和交易日期为字符类型。 data.dtypes
 数据预处理:数据类型转换 由前文可以知道用户ID为数值类型,交易金额和交易日期为字符类型,这里数据类型不对就不能做对应的数据运算,比如交易金额为字符类型就不能求和只能计数,使用astype函数做数据类型转换。 #数值转字符 data['用户id']=data['用户id'].astype(str) #字符转数值 data['交易金额']=data['交易金额'].str[1:].astype(float) #字符转日期 data['交易日期']=pd.to_datetime(data['交易日期'],format='%Y年%m月%d日') data.dtypes
 数据预处理:重复值判断 数据重复会影响数据的计数和求和结果,使用duplicated().any()函数判断是否有重复数据,返回值为False,表明没有重复值数据。 data.duplicated().any()
False 数据预处理:缺失值判断 使用isnull()函数判断是否存在缺失值,由结果判断结果得知性别、年龄、受教育水平均有缺失值。 data.isnull().any(axis=0)#判断各个变量是否有缺失值
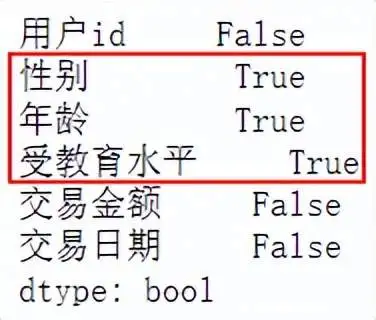 计算各个缺失变量的数量,其中,性别、年龄、受教育水平分别缺失数为136、100、1927。 data.isnull().sum(axis=0)#各个变量缺失值数量
 计算各个变量的缺失值比例,如果该变量的缺失值比例大于30%,则不选用该变量作为分析字段。 data.isnull().sum(axis=0)/data.shape[0]#各个变量缺失值比例
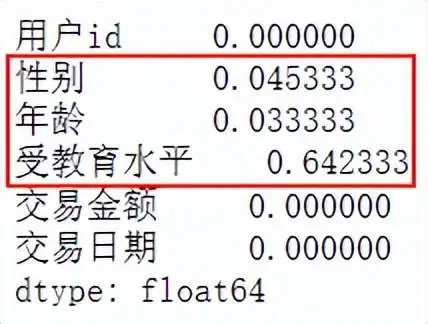 由上面结果可以得知受教育水平该变量缺失比例达64%,远大于30%的缺失值极限值,故该变量直接删除处理。 data.drop(labels='受教育水平',axis=1,inplace=True)#删除缺失比例比较多的一列 data.head()
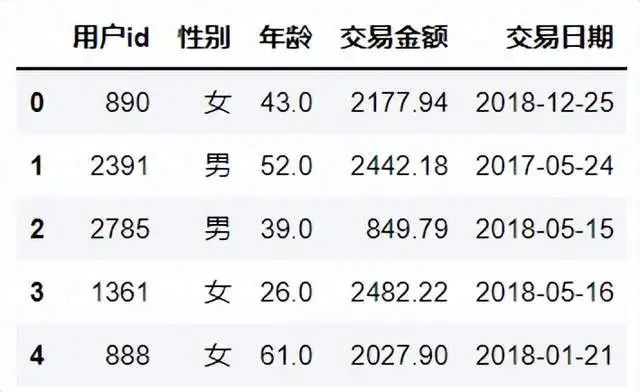 同时,将年龄中缺失值的行进行删除处理,删除受教育水平变量以及删除年龄变量中缺失行数据,最后数据剩下2900行5列。 data_new=data.drop(labels=data.index[data['年龄'].isnull()],axis=0)#删除年龄中的缺失值 data_new.shape
(2900, 5) 除了直接删除缺失行,还可以采用反向选择的方法,反向筛选删除年龄中的缺失值。 data_new1=data.loc[~data[ '年龄'].isnull(),]#反向筛选删除年龄中的缺失值 data_new1.shape
(2900, 5) 除了使用直接删除的方法删除缺失值外,还可以使用众数或者是平均值进行缺失值填充这里对性别使用众数进行缺失值填充,对年龄使用平均值进行缺失值填充。 data.fillna(value={'性别':data['性别'].mode()[0], '年龄':data['年龄'].mean()},inplace=True)
缺失值处理完毕后,再查看缺失值数,此时数据已经填充完整,没有缺失值。 data.isnull().sum(axis=0)
 性别与交易金额的关系 导入matplotlib相关的包绘图。 import matplotlib.pyplot as plt #让图表直接在Jupyter Notebook中展示出来 %matplotlib inline plt.rcParams["font.sans-serif"] = 'SimHei' #中文乱码问题 plt.rcParams['axes.unicode_minus'] = False #负号无法显示 %config InlineBackend.figure_format = 'svg' #设置图表为数量图格式形
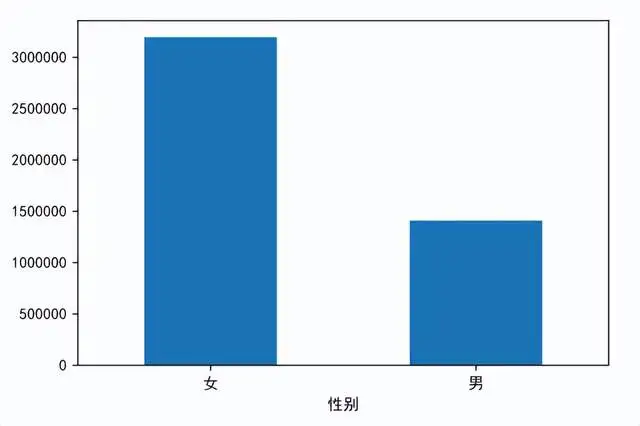
研究不同性别的交易金额大小,按照性别分类对交易金额进行求和,并使用plot.bar命令绘制柱形图,由图可以得出与男性群体相比,女性群体的交易金额大。 sex_price=data.groupby('性别')['交易金额'].sum() sex_price.plot.bar() plt.xticks(rotation=0)
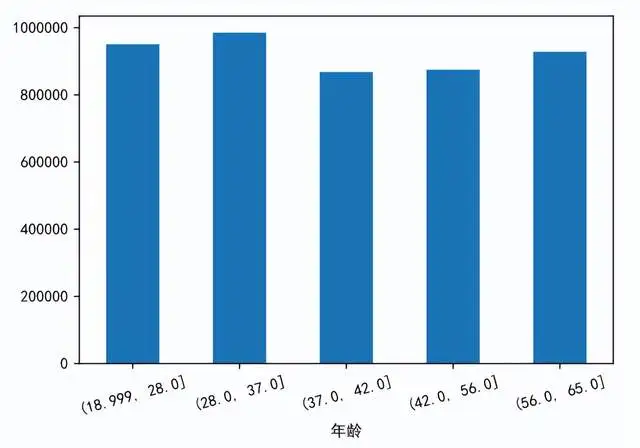
 年龄与交易金额的关系 研究年龄与交易金额的关系,首先用qcut函数进行分组,将年龄分组为5个年龄段,同时按照分组后的年龄段进行分组求和,绘制柱形图可以得知,年龄段在28~37的交易金额最大,年龄段在37~42的交易金额最小。 age_cut=pd.qcut(data['年龄'],5) age_price=data.groupby(age_cut)['交易金额'].sum() age_price.plot.bar() plt.xticks(rotation=15)
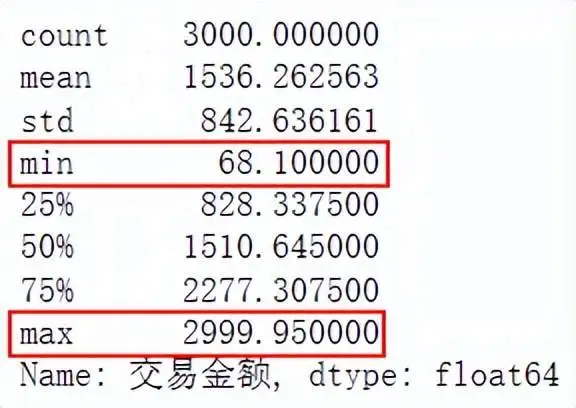
 不同交易金额区间段人数 研究不同交易金额区间段人次,首先对交易金额进行描述统计,由结果可以得知,交易金额的最小值为68.1,最大值为1999.95,由此可以将交易金额的组距设置为500。 data['交易金额'].describe()
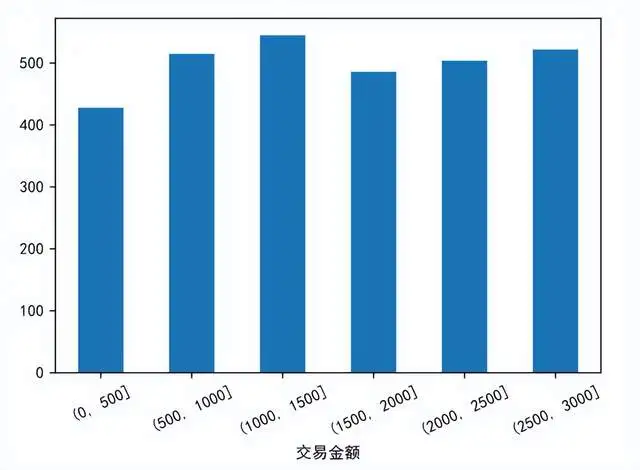
 上面计算出组距,然后使用pd.cut函数将交易金额进行等额分组,设置bins即可等额分组,同时按照分组结果分组计数,绘制柱形图可以得知,交易金额在1000~1500的人数最多,交易金额在0~500的人数最少。 income_cut=pd.cut(data['交易金额'],bins=[0,500,1000,1500,2000,2500,3000]) income_count=data.groupby(income_cut)['用户id'].count() income_count.plot.bar() plt.xticks(rotation=25)
文章源自:大话数据分析
| 






