本帖最后由 喝酸奶不舔盖 于 2024-6-26 17:32 编辑
数据分析时,首先应对数据进行清洗,这里将数据清洗分为重复值处理、缺失值处理、异常值处理三个部分,重复值处理可删除重复的字段,缺失值处理可以用线性插值、填充为0或用均值填充等,异常值处理用描述性分析、散点图、箱形图、直方图查找异常并处理。 本文使用超市商品交易数据,详细介绍重复值处理、缺失值处理、异常值处理的方法,并实际运用数据进行演示,代码操作如下所示。 数据处理 #导入数据 import pandas as pd df=pd.read_csv(r"C:\Users\尚天强\Desktop\超市商品交易.csv",engine="python",encoding="utf-8-sig") df.head()
 1、重复值处理 首先对重复值计数。 df.duplicated().value_counts()
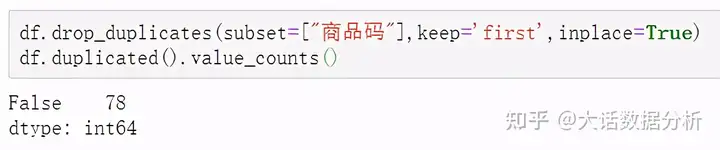
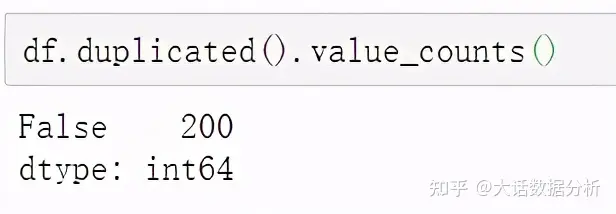 用drop_duplicates的方法对某几列下面的重复行删除,subset:以某列作为基准列,判断是否重复;keep: 保留哪个字段,fisrt参数保留首次出现的数值;inplace: 是否替换当前数据,True选择替换当前数据。 df.drop_duplicates(subset=["商品码"],keep='first',inplace=True) df.duplicated().value_counts()
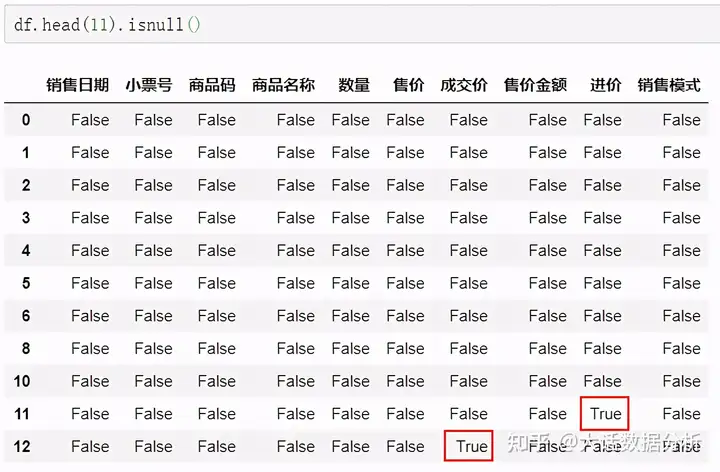
 2、缺失值处理 通过isnull函数看一下是否有空值,结果是有空值的地方显示为True,没有的显示为False。 df.head(11).isnull()
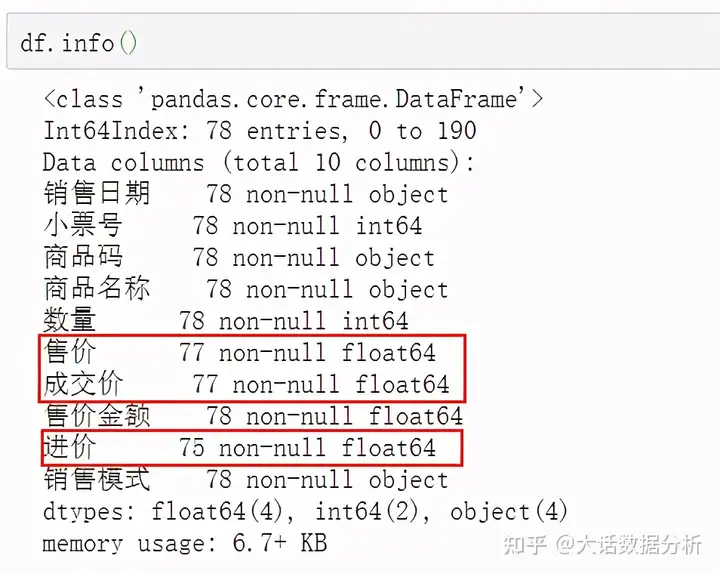
 使用info查看各个字段的属性,标记的部分为缺失的部分。 df.info()
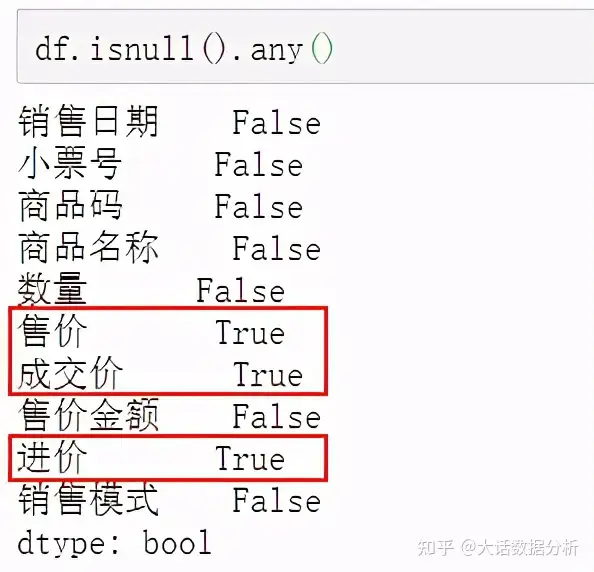
 通过isnull().any()查看每一列是否有空值,True返回缺失值。 df.isnull().any()
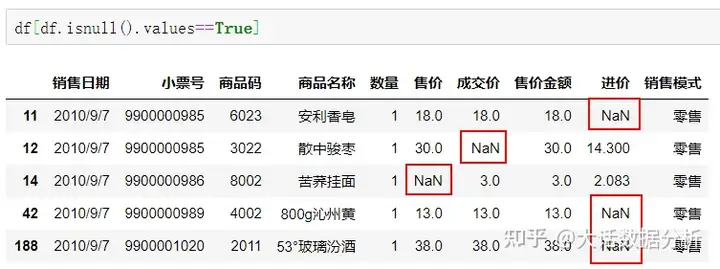
 用df.isnull().values==True来定位哪几行是有空值的。 df[df.isnull().values==True]
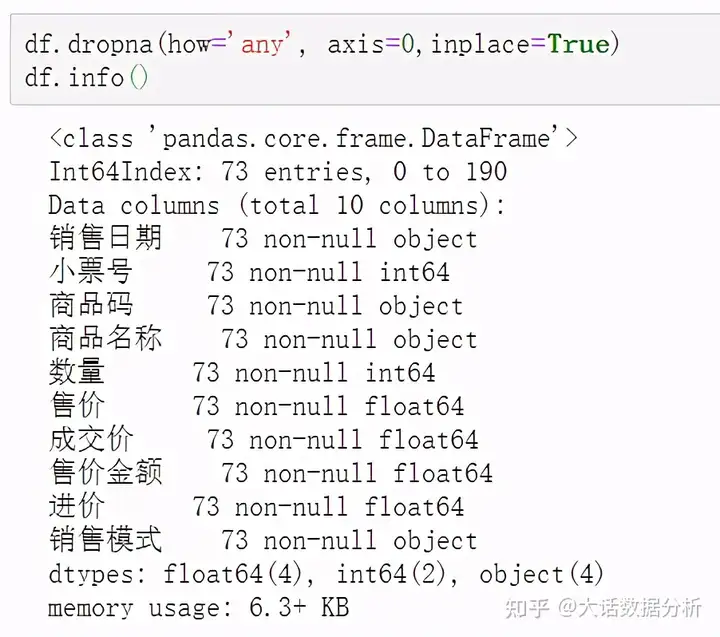
 how='any'只要有一个缺失值就删除,axis=0,删除的是行,默认删除的是行,inplace=True替换原始数据。 df.dropna(how='any', axis=0,inplace=True) df.info()
 fillna(0)用0对缺失值进行填充。 df1=df[df.isnull().values==True] df1.fillna(0)
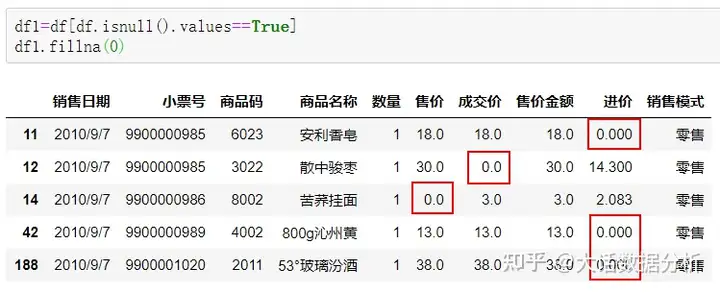 limit用来限定填充的数量。 df1.fillna(0,limit=3)
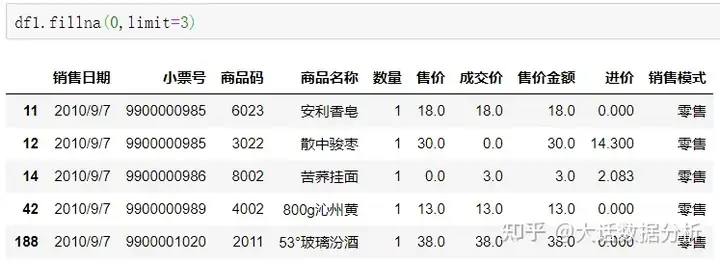 { }对不同的列填充不同的值,其中键作为列,值作为缺失值填充的值。 df1.fillna({"售价":0 ,"成交价":0 ,"进价": "#N/A"})
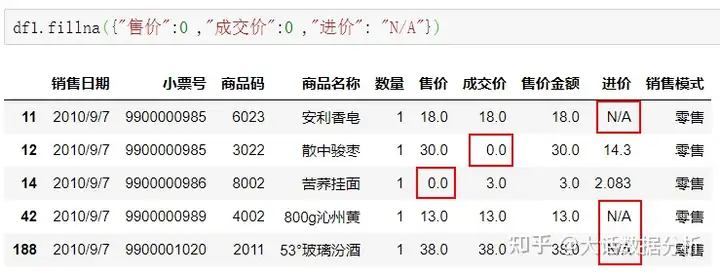 method方法使用ffill,表示用前一个值作为填充的值。 df1.fillna(method="ffill")
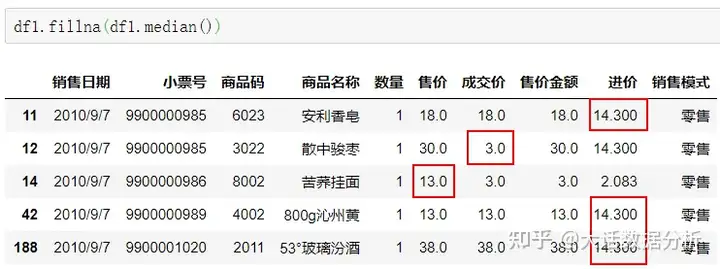
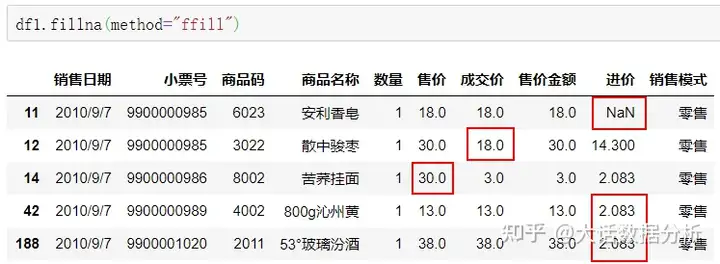 median方法使用中位数的值进行填充。 df1.fillna(df1.median())
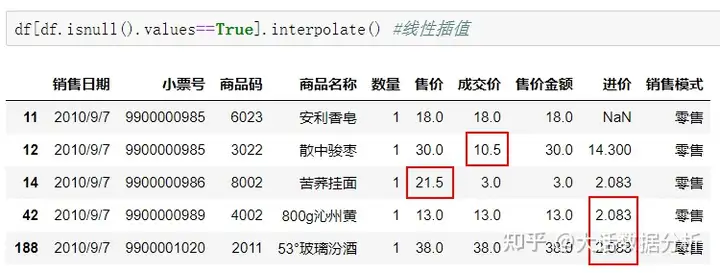
 interpolate表示线性插值。 df[df.isnull().values==True].interpolate() #线性插值
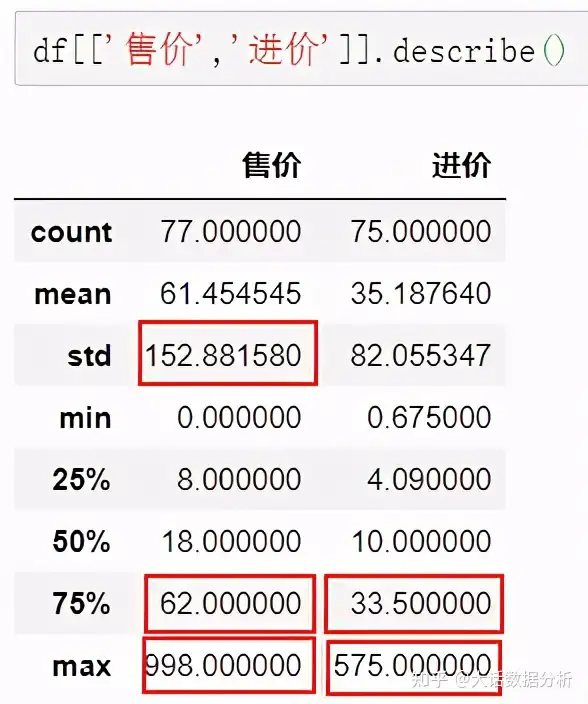
 3、异常值处理 describe( )对统计字段进行描述性分析,从平均值、标准差,看数据的波动情况,最大值查看数据的极值。 df[['售价','进价']].describe()
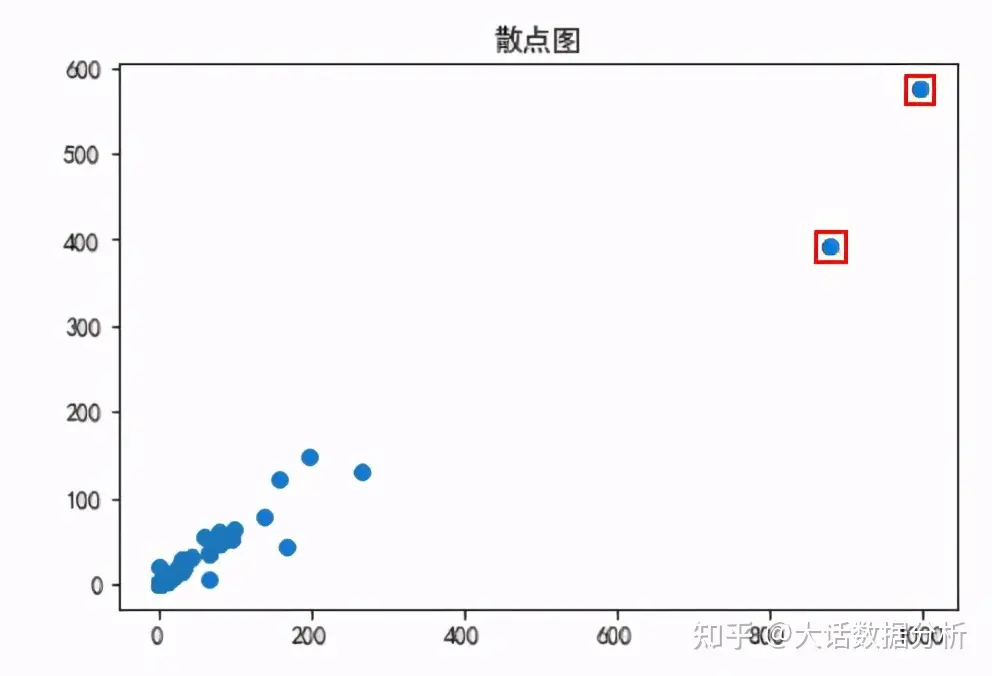
 做出散点图,查看数据中异常的点,图中标记的点就是异常的点。 from matplotlib import pyplot as plt plt.rcParams["font.sans-serif"]='SimHei' #解决中文乱码问题 plt.scatter(df["售价"], df["进价"]) plt.title("散点图",loc = "center") plt.show()
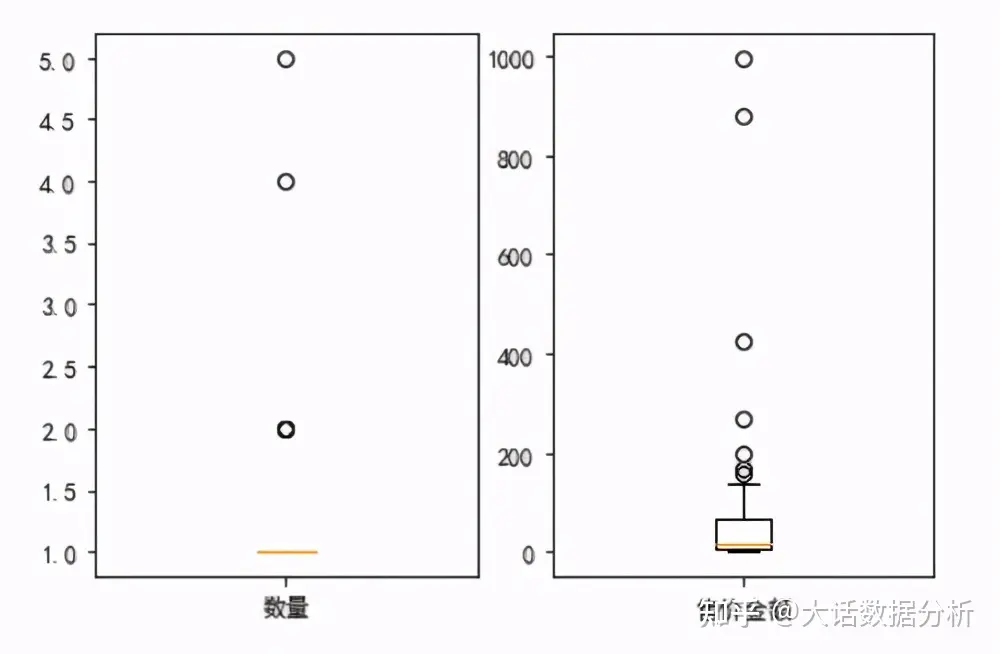
 做出箱线图,反映原始数据分布的特征。 plt.subplot(1,2,1) plt.boxplot(df["数量"],labels = ["数量"]) plt.subplot(1,2,2) plt.boxplot(df["售价金额"],labels = ["售价金额"]) plt.show()
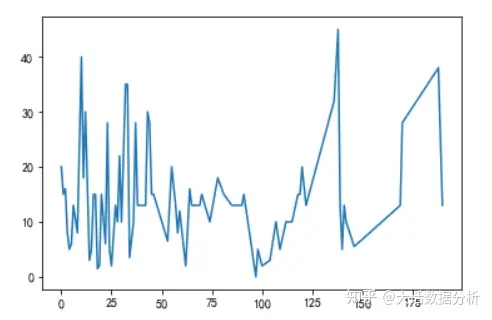
 做售价金额的折线图,售价金额呈波动趋势。 plt.plot(df["售价金额"])
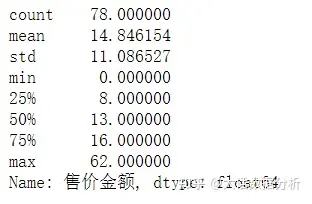
 用箱形图的办法,超过了上四分位1.5倍四分位距或下四分位1.5倍距离都算异常值,用中位数填充。 import numpy as np a = df["售价金额"].quantile(0.75) b = df["售价金额"].quantile(0.25) c = df["售价金额"] c[(c>=(a-b)*1.5+a)|(c<=b-(a-b)*1.5)]=np.nan c.fillna(c.median(),inplace=True) c.describe()
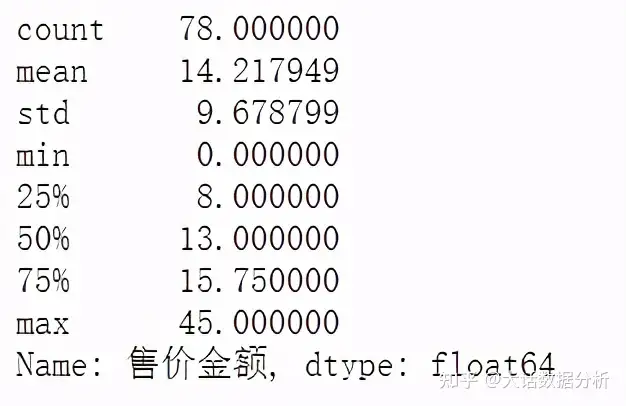
 用标准差和均值,定义超过4倍就算异常值,同样用中位数填充。 a = df["售价金额"].mean()+df["售价金额"].std()*4 b = df["售价金额"].mean()-df["售价金额"].std()*4 c = df["售价金额"] c[(c>=a)|(c<=b)]=np.nan c.fillna(c.median(),inplace=True) c.describe()
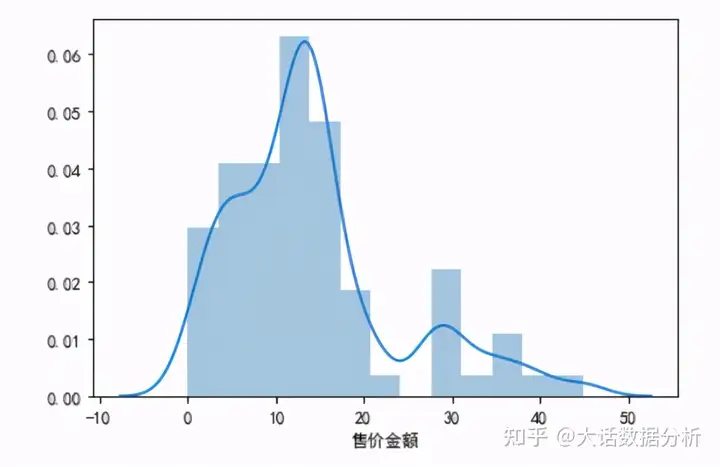
 正态性检验,发现售价金额呈右偏分布,表明售价金额并不是正态分布。 import seaborn as sns sns.distplot(df['售价金额']) #解决负号无法正常显示问题 plt.rcParams["axes.unicode_minus"]= False plt.show()
文章源自:大话数据分析
| 











