张宇航

2019-8-30 18:10:49
发布在社区公告
【专题文章】meta使用场景及疑难问题解决
基于数据量过大的集市数据进行分析时,建议用打meta形式提升报告打开速度。下面是meta中分组分割功能场景实例及疑难问题解决。
|
|
在入集市时,如果数据量非常大建议使用打meta的形式提高报告打开速度。meta是种标签,对数据文件进行分类,打meta后在读取数据的时候,就不需要读取所有文件,只需要读取有meta过滤后的文件就可以,加快打开速度。
打好的meta会存放在安装目录/Yonghong/bihome/cloud中的qry_naming.m文件中(qry_sub.m 是map节点存储的zb信息,qry_naming.m是naming节点存储的集市文件夹信息)。 |
|
注:setMeta('名字','值');
名字即"MARKET",值即"West"。 |
|
|
| 平均分割只能选择一个分割列,分割份数为整数,如:分组分割不能填写分割份数,可以选择多个分割列。为了不影响导入数据的效率,建议分割列的列数不超过10。 |
|
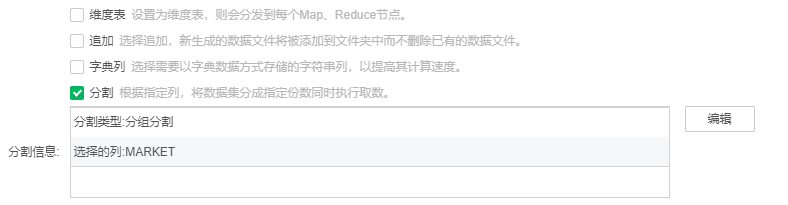
| 分组分割可以自动生成 Meta 信息,以方便对数据集市中的数据进行过滤。其中,Meta中的key为分割列对应的列名,Meta中的value 为分割列对应的值。 |
|
| 服务器类型 | 节点类型 | C核数 | E核数 | 服务器内存 | 永洪分配内存 | jdk版本 | | linux | CNR | 8 | 4 | 62 | 34 | 1.9 | | linux | M | 4 | 4 | 62 | 22 | 1.9 |
|
|
(1)数据量
集市数据总行数4.7亿,最大集市文件数据总行数约1亿行,每天以150w增量增加,通过表格展示明细数据,时间跨度两个月,单并发情况下,查看单张报表最快需要20+s。
(2)并发量
在永洪未知的情况下,该客户使用门户功能,制作了一个由4张报告组合的门户,并将该门户开放给各个网省使用,用户并发从平时的10个激增到300+。 |
|
| 访问产品时查看报告、制作报告等模块均处于加载中,产品处于卡死状态。 |
|
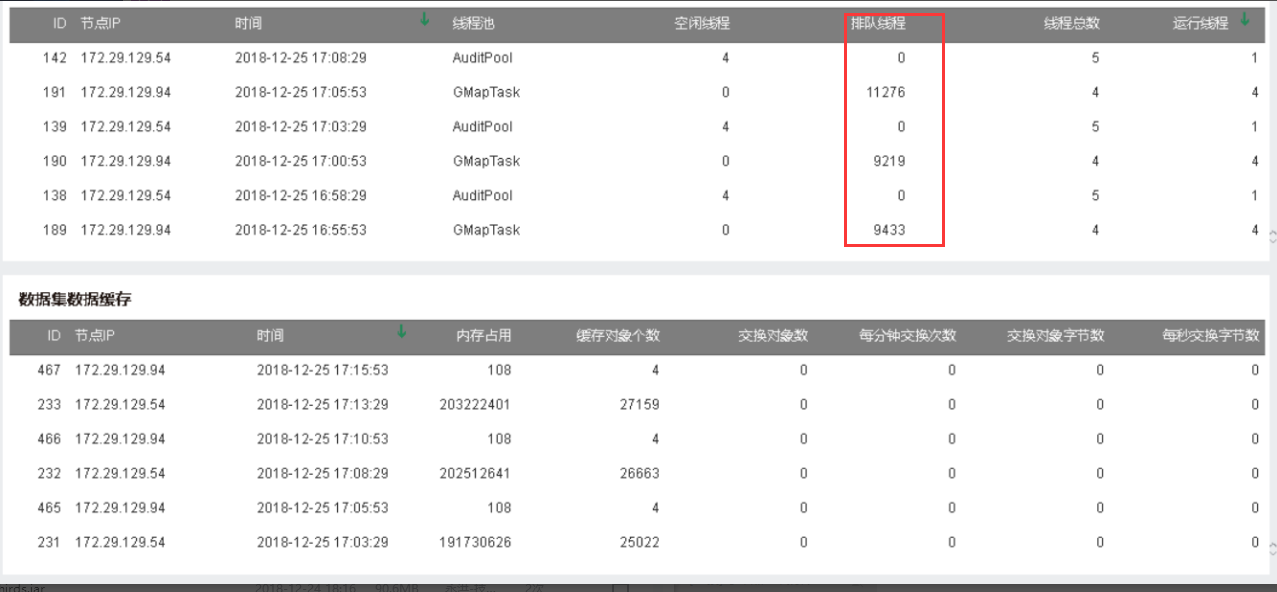
| 并发约300时,产品访问打不开制作报告、查看报告等,即产品卡死不能使用,监控系统中“产品运行状态监控”截图如下,排队线程高达10000+。 |
|
| 根据客户目前的集群环境无法支撑目前实际的数据量以及并发量。 |
|
| 发送集群评估调查问卷了解客户实际使用场景,最大数据量约1亿、日增量数据150w行,并发量约400、分析近两个月的明细数据、期望报表响应时间为3s内,根据客户场景进行评估后,如果需要支持目前的数据量以及并发量,需要集群配置如下 |
|
| 节点角色 | 服务器内存 | CPU核数 | 磁盘 | 永洪分配内存 | 核数 | C | 128G(至少64G) | 16core | 500G | 80G(至少42G) | C12-E0 | CN | 128G(至少64G) | 16core | 500G | 80G(至少42G) | C12-E12 | MR | 128G(至少64G) | 16core | 1T | 80G(至少42G) | C4-E12 | MR | 128G(至少64G) | 16core | 1T | 80G(至少42G) | C4-E12 | MR | 128G(至少64G) | 16core | 1T | 80G(至少42G) | C4-E12 | MR | 128G(至少64G) | 16core | 1T | 80G(至少42G) | C4-E12 |
|
|
| 由于客户目前无法立刻申请到这么多台可用服务器,并且要尽快恢复用户的正常使用,给出以下临时解决方案。 |
|
根据当前的两台服务器缩减集群,获知客户环境两台服务器核数均为16核,为缓解并发过高时产品访问的效率,增加C和E的核数,增加后客户目前环境状态
| 服务器类型 | 节点类型 | C核数 | E核数 | 服务器内存 | 永洪分配内存 | jdk版本 | | linux | CNR | 12 | 12 | 62 | 40 | 1.9 | | linux | M | 6 | 12 | 62 | 40 | 1.9 |
|
|
| 根据目前集群按比例缩减数据量,原分析明细数据时间跨度为两个月,数据量1亿,控制分析明细数据时间跨度为两周(14天),数据量在2500w左右。 |
|
| 对数据量过大的集市数据进行分组分割meta操作,客户目前使用的方案如下,供参考。 |
|
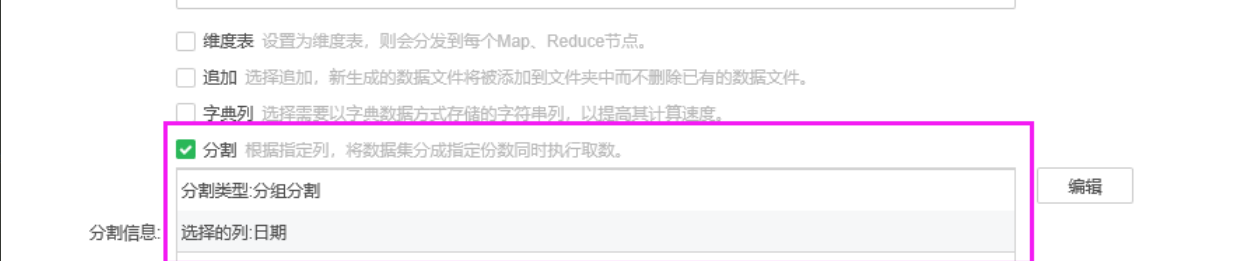
只勾选分组分割,选择到分组分割字段(客户使用的字段为“日期”,该字段为字符串类型,样例数据为“20181226”);
不要勾选追加。 |
|
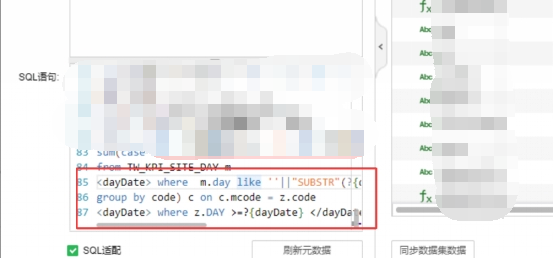
| 3.4.3.2如果需要进行sql传参,例如客户场景需要向数据库传递时间参数dayDate,获取从dayDate至当天前一天的所有数据,sql主要部分见下图 |
|
这种情况需要给参数设置默认值,用于传给sql数据集中进行sql传参工作,如果不传递参数默认值,会导致增量任务的集市文件夹中没有数据,例如客户场景给dayDate参数设置的默认值为“20181101”。 |
|
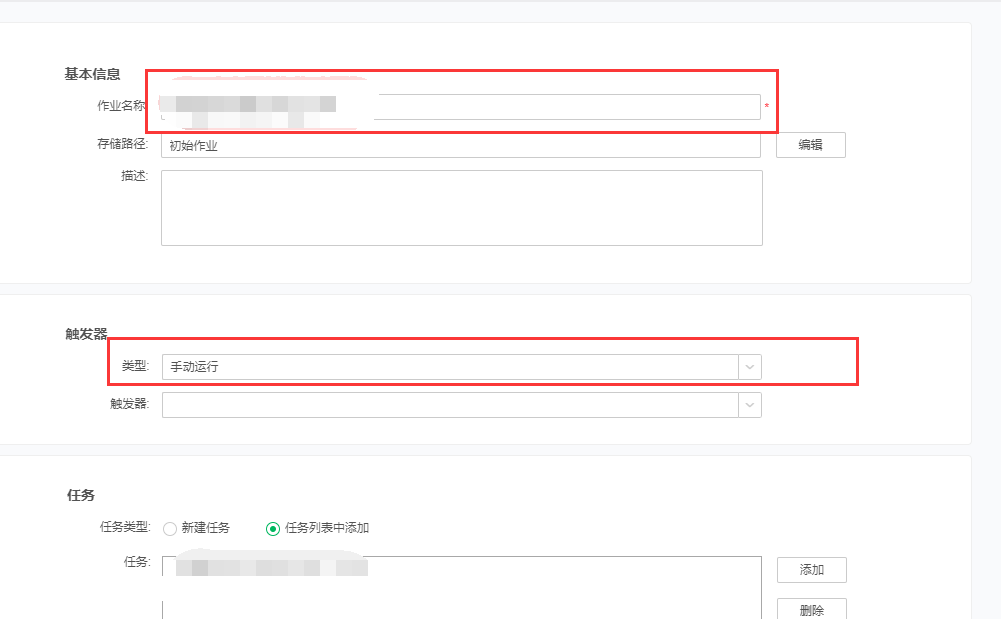
3.4.3.3执行该定时任务,进行初始数据的导入工作
|
|
勾选【分割】选项,选择分组分割,选择到日期字段
勾选【追加】选项 |
|
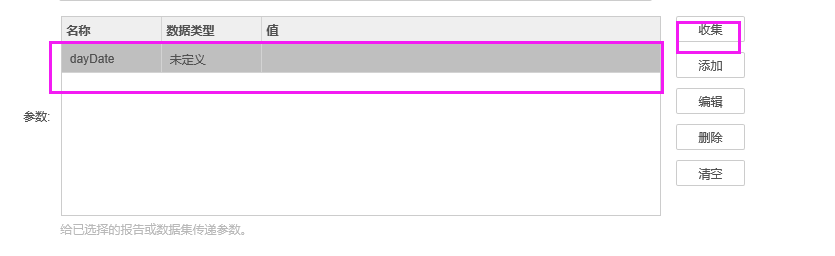
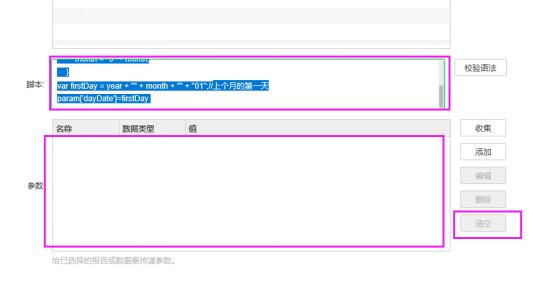
3.4.3.5在包含sql传参时,需要清空“参数”中的默认值配置,在“脚本”中对参数进行动态赋值。例如客户场景,点击“参数”后的“清空”按钮,将dayDate参数默认值设置删除,在“脚本”中加入脚本
|
|
var nowdays = new Date();
var beforedays = dateAdd(nowdays,"dayofyear",-1)
var a=formatDate(beforedays,"yyyyMMdd");
param['dayDate']=a //当天的前一天,即增量导入当天前一天的数据 |
|
3.4.3.6根据需求设置定时任务触发器信息,客户环境因为每日会有增量150w行数据的需求,所以设置为每天早晨8:00运行增量任务
|
|
| 注:初始导入,后续勾选追加选项后,该增量任务每天只能运行一次,如果多次运行,会出现数据重复的现象。 |
|
|
3.4.4如果出现重复导入的情况,如何清理重复数据
|
|
| 打开历史作业状态①,找到定时任务第二次运行的一行信息,例如本地是增量任务“脚本打meta入集市”一天执行了两次,点击②打开任务运行结果界面,将本次执行的所有数据点击④“全部删除”,删除重复数据。 |
|
| 集群运行稳定,单并发时查看原20+s打开的报表可以达到2s内响应,速度提升10倍,并发量提高至200-300时,依然可以稳定运行。 |
|
| 带有复杂sql语句(内部有join和大分组的情况)的sql数据集,通过分组分割的形式、利用脚本获取每天的数据增量入集市,突然出现任务“执行数据超时”的情况。 |
|
| 5.2.1在C节点bi.properties里面针对不同的数据库增加连接不重用配置,重启生效;或者直接在管理系统-系统参数配置中进行调整,无需重启;验证问题是否解决 |
|
conn.db2.reuse=false
conn.hive.reuse=false
conn.mysql.reuse=false
conn.oracle.rac.reuse=false
conn.sqlserver.reuse=false
conn.impala.reuse=false |
|
| 5.2.2添加或修改execute.data.timeout=3600000;sql数据集执行数据的过期时间,至足以支撑数据库数据返回给产品 |
|
| 本身的sql数据集sql部分执行需要27min,在进行分组分割时,产品还会在sql语句的最外层包裹一层进行分组的sql语句,由于新增这部分语句,导致复杂sql 的分组入集市功能时间大大增加。 |
|
| 复制sql数据集存为副本数据集,并使用定时任务运行增量导入数据,将数据放入数据集市,然后基于数据集市数据集分组再入集市,操作步骤如下。 |
|
基本思想:
绕过执行sql获取数据入集市,使用已经入到集市的数据再进行增量打meta。以下操作在2.4.3meta配置基础上按照 4.4 解决方案-(1)进行修改。 |
|
选择为“增量导入数据”;
选择复制后的sql数据集P;
新建文件夹1;
不勾选维度表、追加、字典列、分割;
不设置任何过滤器、脚本;
如果需要进行sql传参,例如客户场景需要向数据库传递时间参数dayDate,获取从dayDate至当天前一天的所有数据,集市数据已经包含20181231至该日期前两个月的数据,恢复数据当天日期为20190103,缺失数据为20190101、20190102两天的数据,这种情况需要给参数设置默认值即为20190101,用于获取20190101和20190102的数据,即dayDate参数设置的默认值为“20190101”
保存任务,执行该任务。 |
|
5.5.1.3待新建的增量任务002执行完成后,根据实际需求设置触发器信息,使用集市文件夹1新建集市数据集A,此时集市数据集A中的数据是20190101-20190102两天的
|
|
5.5.1.4由于数据集市数据集不可进行“同步数据集数据”、“增量导入数据”操作,但是还需要使用集市数据集中的数据怎么办呢,接下来关键点引入----Data Mart
|
|
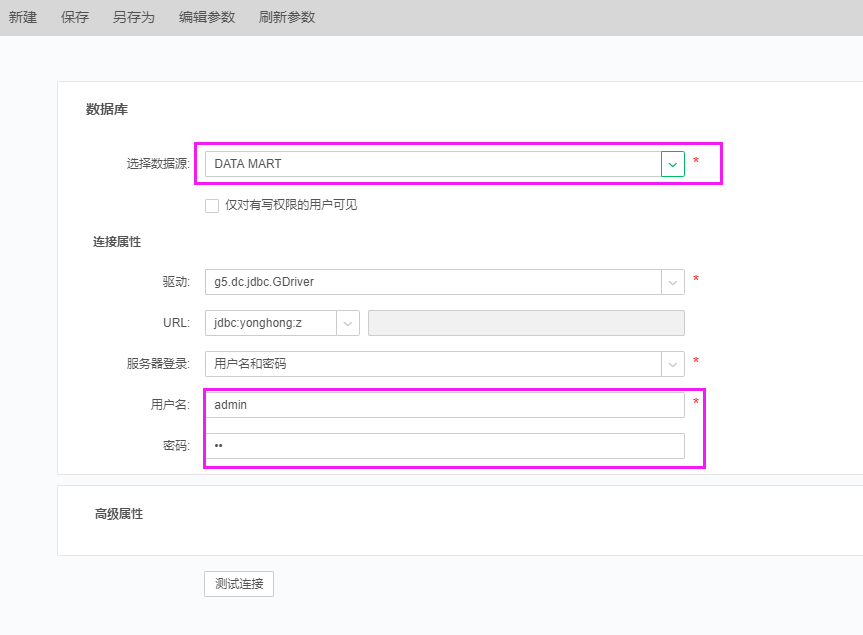
| 新建DATA MART数据源,填入正确的驱动、URL、用户信息(用户信息为访问永洪的账号及密码),保存为数据源“DataMart”。 |
|
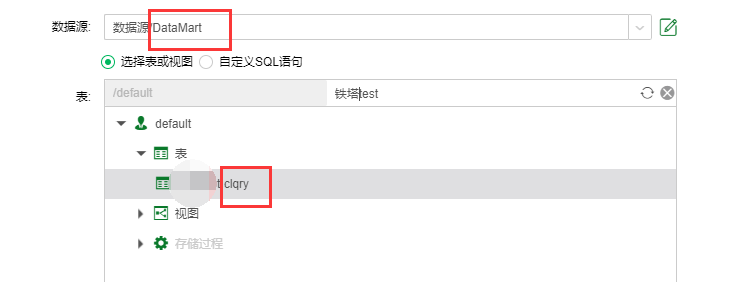
| 新建sql数据集Q,数据源选择为DataMart,搜索到集市数据集A,刷新元数据,保存,此时sql数据集Q中的数据是20190101-20190102两天的。 |
|
选择数据集为sql数据集Q;
不添加任何过滤器、脚本、参数;
保存任务,执行该任务。 |
|
5.5.1.6增量任务001执行完成后,查看通过增量任务001入集市后的集市数据集是否已经包含20190101-20190102两天的新数据
|
|
5.5.2恢复数据后,修改两个定时任务配置用于后续数据入集市工作,操作步骤如下
|
|
5.5.2.1在增量任务002中去掉所有参数默认值并添加脚本用于后续增量数据使用。客户场景是每日增量前一天的数据,脚本设置参数的值即为当天的前一天日期
|
|
脚本内容:
var nowdays = new Date();
var beforedays = dateAdd(nowdays,"dayofyear",-1)
var a=formatDate(beforedays,"yyyyMMdd");
param['dayDate']=a //昨天日期,即增量导入昨天的数据 |
|
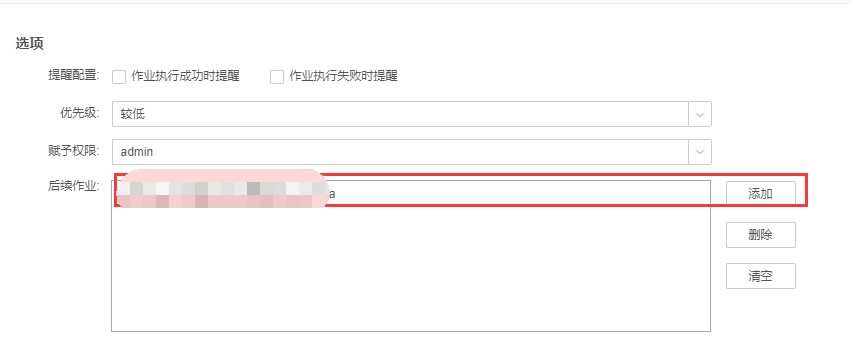
5.5.2.2添加增量任务002的后续作业为增量任务001
|
|
| 编辑增量任务001触发器为手动运行,因为在增量任务002定时运行完成后,即会自动执行后续作业任务001,保存任务。 |
|
| 缺失的20190101-20190102的数据已经恢复,并且在20190104日查看数据情况,定时任务稳定执行,20190103日数据也通过定时任务入集市完成。 |
|
集市数据量大导致查看报告速度慢怎么办?
1、分析入集市后的数据时,如果数据量非常大可以使用打meta形式提高报告打开速度;
2、在集群集市核数过少时,建议对集群进行扩容,增加集市核数;
3、在并发量过高时,建议增加线程C的核数;
4、通过减少分析的明细数据量来提高报告打开速度。 |
|
注:永洪BI标准产品使用入集市操作不建议超过一次。
例如:使用多个集市数据集建立组合查询后,再将组合查询入集市组合数据集会将两个数据源的数据都抓到内存中,然后再进行计算,占用大量内存的同时,也有可能会在服务器上生成大量临时文件,这是有违永洪产品使用最佳实践的。
所以,在非特殊情况下,是不建议入集市操作超过一次的哟。 |
|
|
|
免责声明:本文不代表本站立场,且不构成任何建议,请谨慎对待。
版权声明:作者保留权利,不代表本站立场。






.png)
.png)



.png)
.gif)
.gif)
.gif)
.gif)